Cátedra iDanae: Modelización por componentes
La Cátedra iDanae (inteligencia, datos, análisis y estrategia) en Big Data y Analytics, creada en el marco de colaboración de la Universidad Politécnica de Madrid (UPM) y Management Solutions, publica su newsletter trimestral correspondiente al 3T21 sobre Algoritmos de Machine Learning
Modelización por componentes
Introducción
La transformación digital y los grandes avances en el ámbito de Data Science están impulsando el desarrollo de modelos de negocio basados en datos y en Inteligencia Artificial (IA). Por ejemplo, la inversión mundial total realizada en IA aumentó un 40% en 2020 con respecto a 2019, con un total de 67.900 millones de dólares. El retorno esperado justifica esta inversión: el 63% de las empresas que han adoptado el uso de modelos de Machine Learning en sus unidades de negocio informan de un aumento de los ingresos, siendo de más del 6% para aproximadamente la mitad de ellas. Asimismo, el 44% de las empresas reportan un ahorro de costes, siendo superior al 10%para aproximadamente la mitad de ellas.
El desarrollo del aprendizaje automático y su incorporación en el ámbito empresarial, tanto público como privado, ha llevado a que distintos reguladores centren su atención en la prevención, control y mitigación de los potenciales riesgos que pueden derivarse de ello. Por ejemplo, en Europa, la Comisión Europea ha desarrollado documentos como una propuesta de Reglamento sobre los usos de la Inteligencia Artificial o el Whitepaper sobre la Inteligencia Artificial; asimismo, la EBA publicó un informe sobre Big Data y Advanced Analytics5, donde expone los principales pilares de confianza sobre los que debería basarse un framework de desarrollo de modelos basado en IA; igualmente, la EIOPA publicó un informe sobre los principios de gobernanza de la IA. En Estados Unidos, el National Science and Technology Council (NSTC) sentó precedente en 2016 para la creación de leyes que regulen los riesgos de la IA, y en los últimos años se han publicado informes y recomendaciones como: National Security Commission on Artificial Intelligence, Recommendations on the Ethical Use of Artificial Intelligence by the Department of Defense o Guidance for Regulation of Artificial Intelligence Applications (borrador actualmente en proceso de consulta). De forma paralela, los gobiernos locales y autoridades supranacionales están invirtiendo en el desarrollo de programas de inteligencia artificial y desarrollo digital.
Tanto la construcción como la implantación de un modelo de Machine Learning pueden ser procesos de una complejidad elevada. Además, resulta necesaria la monitorización continua para garantizar que dichos procesos se ejecutan con éxito. Esto puede conllevar el incremento de otros costes o riesgos asociados: algunos estudios muestran cómo es fácil incurrir en costes de mantenimiento muy elevados. Por tanto, la incorporación y el creciente desarrollo de las técnicas de modelización avanzada vienen acompañados de la búsqueda de la eficiencia en los desarrollos de los modelos y su puesta en producción. En particular, al igual que surgió la metodología DevOps en relación al desarrollo de software, en el ámbito de Machine Learning, inspirado en DevOps, se ha originado la metodología de MLOps: una metodología de desarrollo ágil de aplicaciones basadas en algoritmos avanzados de Machine Learning, que proporciona los distintos elementos y roles profesionales que deben estar presentes en las distintas fases del desarrollo.
A su vez, en el ámbito de los proyectos de Machine Learning destaca la creciente incorporación de sistemas, marcos de desarrollo, lenguajes de programación open-source, y el aprovechamiento de las capacidades computacionales, entre otros. Ello ha originado nuevos modelos de negocio y estrategias de implantación (por ejemplo, la externalización a servicios en la nube, que facilita el disponer de una infraestructura tecnológica y de las capacidades computacionales necesarias para los desarrollos). La disrupción del Machine Learning, la metodología MLOps y los ecosistemas open-source motivan la aparición de una meta-tendencia en la que subyace un cambio en el paradigma de modelización, que puede materializarse con la modelización por componentes. Estas componentes se pueden entender como el elemento atómico básico necesario en cualquiera de las fases de modelización, siendo totalmente independientes entre ellas. Su utilización en conjunto permitirá una automatización de los procesos, generando sistemas ordenados y trazables.
Por todo ello, en este estudio se pretende aportar una visión sobre el concepto de modelización por componentes y los beneficios asociados, así como aportar una descripción de algunos elementos técnicos asociados, como el proceso de componentización y ejemplos de arquitectura tecnológica.
¿Qué es la modelización por componentes?
El concepto de modelización por componentes tiene su origen en la Ingeniería de software basada en componentes
(CBSE), la cual surgió en la década de 1990 como un enfoque innovador para el desarrollo de software.
La CBSE se fundamenta en la reutilización de entidades denominadas componentes de software, que se definen como entidades ejecutables independientes que pueden estar formadas por uno o más objetos ejecutables. Apoyándose en esta definición, la CBSE hace hincapié en la idea de separar funcionalidades específicas respecto a la prestación principal que proporciona el software en su conjunto.
La aparición de la CBSE presenta una diferencia fundamental con respecto a la programación orientada a objetos (OOP): las disciplinas de OOP están enfocadas en el modelado de interacciones del mundo real, e intentan identificar los “sustantivos” (quién ejecuta) y los “verbos” (qué acción se realiza) durante el levantamiento de requerimientos, con el objetivo de traducir esos conceptos en clases y métodos; por el contrario, la CBSE no hace tales asunciones, y en lugar de ello expresa que los desarrolladores deben construir el sistema combinando componentes prefabricadas entre sí. Esto motivó que algunos hablaran de un nuevo paradigma de programación, como por ejemplo, la teoría de programación literaria de Donald Knuth, o el artículo The Cruelty of Really Teaching Computer Science de Edsger Dijkstra.
Durante los últimos años, causas similares han impulsado el desarrollo de la modelización por componentes, entre las que cabe destacar: (1) la redundancia en los desarrollos17, (2) la posibilidad de que existan errores en los nuevos desarrollos y (3) la búsqueda eficiente de estrategias que puedan descartar errores en el uso de la analítica avanzada; además de los beneficios inherentes al uso de una estrategia de modelización por componentes.
La modelización por componentes tiene como objetivo separar todos los procesos que deben llevarse a cabo bajo las fases de un framework de modelización avanzada. La metodología MLOps ya hace esta tarea, dividiendo esencialmente estas fases en dos grandes grupos: Desarrollo y Producción (véase figura 1).
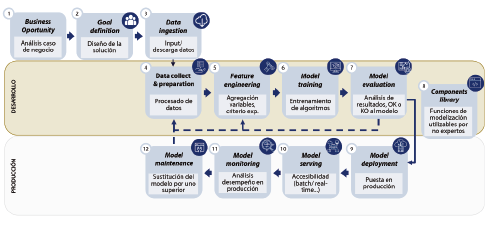
Una componente de modelización es un módulo que encapsula un conjunto de funciones o procesos relacionados para realizar las tareas en la resolución de un caso de uso concreto. Por ejemplo, para todo caso de uso siempre debe realizarse un procesamiento de los datos (fase del framework), que implica la aplicación de distintos procesos sobre los datos, entre ellos: missings, outliers, correlaciones o selección de variables. Cada una de estas tareas para esta fase18, puede ser objeto de una componente de modelización que, combinadas en un orden concreto, permiten una automatización flexible del proceso de modelización.
Por último, cada componente recibe un input determinado (un dataset y un conjunto de parámetros), y se encarga de ejecutar la tarea específica para la que ha sido programada, devolviendo otro dataset con el resultado de la tarea aplicada. Así, la modelización por componentes es un proceso basado en datos, considerándose un enfoque clave en la adopción de una cultura basada en datos en cualquier organización.
Beneficios
La automatización de los procesos relacionados con la aplicación de técnicas de analítica avanzada se ha desarrollado con intensidad en los últimos años por múltiples motivos. Según Gartner, más del 50% de las tareas de data science estarán automatizadas en el año 2025. A continuación, se exponen las principales ventajas que aporta la componentización de los procesos de modelización frente al desarrollo de un workflow específico para cada problema:
- Estandarización del desarrollo de componentes. El objetivo de la estandarización radica en asegurar la uniformidad de la totalidad de las componentes utilizadas en la modelización, siguiendo unas guías establecidas antes de iniciar el proceso de creación de las mismas. Esta estandarización ayuda a reducir la frecuencia de errores, mejorar la comparabilidad, y facilitar las tareas de mantenimiento y revisión.
- Mejora de la calidad y especialización. El focalizar los esfuerzos en el desarrollo de cada componente una única vez propicia un aumento notable en su calidad, puesto que cada componente será desarrollada por un especialista en el ámbito de conocimiento correspondiente.
- Mejora de las eficiencias. El desarrollo de cada componente una única vez conlleva una mejora de la eficiencia en las funciones de desarrollo, validación y, en su caso, auditoría. De este modo, el trabajo futuro se puede focalizar en la correcta aplicación de cada una de las componentes, en lugar de la revisión de la construcción.
- Mejora de la usabilidad. La modelización por componentes permite a usuarios con un perfil no técnico o no especializado hacer uso de los procesos de modelización, sin necesidad de disponer de conocimientos en programación. En esta línea, este enfoque proporciona tanto una elevada facilidad de aprendizaje22 como de uso.
- Escalabilidad. Este enfoque facilita una adaptación a las necesidades de rendimiento específicas en cada momento, lo que brinda la posibilidad de un desarrollo basado en un host interno o en cloud, tanto para cada filial de una empresa como por ámbitos geográficos.
Estas ventajas han impulsado un cambio notorio en la forma de abordar el desarrollo, la validación y la implementación de los modelos, con vistas hacia la automatización de los procesos de modelización.
El proceso de componentización
Las distintas fases del proceso de construcción de un modelo presentan dedicaciones de tiempo desiguales entre ellas. En general, las tareas previas de análisis, preparación, limpieza, organización y tratamiento de los datos suelen consumir una gran cantidad de tiempo y recursos, de forma que las tareas de Knowledge Discovery o el refinamiento de algoritmos suelen quedar relegadas a un segundo plano o a un estadio posterior.
Actualmente se observa una tendencia clara hacia la automatización de los procesos relacionados con la aplicación de técnicas de advanced analytics, cuyo objetivo es realizar un examen autónomo o semi-autónomo de los datos utilizando técnicas avanzadas como la minería de datos y texto, Machine Learning, visualizaciones, clustering o procesamiento de lenguaje natural (NLP), entre otros. La automatización de un flujo de modelización es posible mediante dos procesos complementarios, que de forma habitual terminan combinándose: (1) la componentización de los distintos procesos en elementos segregados, y (2) la ejecución automática de estas componentes, sistematizándolos a través de reglas preestablecidas y técnicas estadísticas.
El proceso de componentización de un sistema de modelización puede estructurarse en las siguientes fases: (1) preparación, (2) definición de la estructura del sistema, (3) construcción del sistema y codificación, (4) validación, y (5) desarrollo de la herramienta de explotación.
Preparación
El primer paso para la construcción de un sistema de componentes es entender el estado actual del proceso y realizar una fase preparatoria, que debería incluir al menos el siguiente conjunto de tareas:
- El análisis del marco de modelización actual.
- La identificación de los procesos afectados.
- La clasificación de los procesos dentro del marco de modelización (que pueden ser transversales o aislados)
- La identificación de los procesos susceptibles de componentización y el análisis de su grado de automatización actual.
- La selección de los equipos especialistas y los owners de los procesos que se van a componentizar.
Definición de la estructura del sistema
La segunda fase consiste en la definición de la estructura del sistema de componentes. Una manera eficiente y estructurada de aterrizar la componentización de un proceso es definir una jerarquía de componentes en niveles. Una propuesta de agregación por componentes podría estructurarse de la siguiente manera:
- Nivel 0: cada una de las componentes de esta categoría recibe un input determinado con el objetivo de ejecutar una tarea específica. Es el nivel más elemental en la jerarquía de componentes. Por ejemplo, tal y como se ilustraba en el apartado 2, procesos como el análisis de missings, outliers o correlaciones, serían tareas específicas que corresponderían a una componente de nivel 0.
- Nivel 1: las componentes de nivel 1 son agregaciones de componentes de nivel 0 y, por tanto, son componentes capaces de abordar un problema mayor o más complejo. Esta agregación se realiza en un orden específico para ejecutar determinadas tareas que suelen realizarse con asiduidad (por ejemplo, la depuración de datos).
- Nivel 2: es el mayor nivel de agregación. Estas componentes están conformadas por agrupaciones de componentes de nivel 1, y por ello son capaces de abordar tareas completas.
Bajo este esquema, los cambios o mejoras que se realizan en una componente se transmiten de forma automática hacia las componentes de niveles superiores de los que forma parte, generando así un sistema que se puede mantener y evolucionar de forma eficiente.
Construcción del sistema y codificación
Una vez realizadas las fases anteriores, es necesario programar el código de cada uno de los procesos automatizables. Esta programación debe hacerse siguiendo los estándares del desarrollo de proyectos de ingeniería del software para garantizar la corrección.
Una alternativa que dota de flexibilidad a la arquitectura del sistema es empaquetar las funcionalidades de cada componente en una API (Application Programming Interface). Esto permite a un usuario o proceso utilizar una función a través de la red como si de una librería propia se tratase. La comunicación con una API se realiza a través de una petición tipo GET o POST (ambos son métodos dentro del protocolo usados para el intercambio de información), que contienen la información siguiendo un formato definido (normalmente en formato JSON).
Las ventajas más relevantes de usar este tipo de metodología se pueden resumir en las siguientes:
- Independencia del lenguaje de programación. Cada una de las componentes puede estar desarrollada en un lenguaje distinto, ya que el proceso de lógica y el de comunicación están separados, y el protocolo de comunicación es común a todas.
- Flexibilidad. Todas las tareas están identificadas a través de una API individual, de forma que se pueden mejorar, añadir o reestructurar procesos y flujos de información sin afectar al desarrollo completo de la herramienta.
- Escalabilidad. Se puede escalar los requerimientos computacionales de un servicio o una funcionalidad de forma independiente al resto para satisfacer una demanda concreta sin afectar al resto.
Validación
Tras el proceso de “apificación” se ha de realizar una batería de pruebas que cubra la validación tanto de las componentes como de las APIs. Este conjunto de pruebas se ejecuta con distintos tipos de datos y parámetros, de forma que sea posible probar el correcto funcionamiento de cada componente. En las pruebas también se recogen errores creados a priori para comprobar que están controlados y que se genera un mensaje de error visible para el usuario.
Desarrollo de la herramienta de explotación
En esta fase (que se suele realizar en paralelo a la fase anterior) se construye una herramienta que permita explotar y utilizar las componentes. Para ello, es necesario desarrollar un front-end donde se implementen distintas funcionalidades, como la sección de administración (para la gestión de usuarios, configuración, etc.), la usabilidad de cada componente (que permita ejecutarla, así como visualizar el código y reportar el log del proceso), y la construcción de los flujos de modelización. Finalmente, se realiza el despliegue de la herramienta desarrollada en el entorno elegido.
Antes de realizar el despliegue de la herramienta en una organización, es conveniente realizar pruebas piloto (que incluye un conjunto estandarizado de pruebas, así como el uso por un grupo reducido de personas) mediante las cuales se pueda testear el correcto despliegue y funcionamiento de la misma dentro del entorno de implementación elegido.
Junto con el desarrollo de la herramienta, es importante crear guías funcionales y técnicas para la consulta por distintos usuarios una vez desplegada la herramienta. Estas guías pueden también utilizarse como base para el programa de formación destinado al usuario final.
La integración de todos los elementos descritos puede realizarse a través de un desarrollo in-house, o bien a través de la adquisición de una herramienta a un tercero. No obstante, en cualquiera de estas alternativas se ha de disponer de la flexibilidad para poder adaptar la herramienta a la infraestructura tecnológica y a las necesidades de componentización de los usuarios.
Hacia la democratización de la modelización
La modelización por componentes contribuye a la democratización de los procesos de modelización. En líneas generales, el concepto de democratización hace referencia al proceso de hacer accesible un conjunto de recursos a un amplio número de colectivos, bien dentro o fuera de la organización
(por ejemplo, así ocurre con la democratización de los datos, poniéndolos a su disposición para que los observen, analicen, o utilicen en la toma de decisiones). Por tanto, la democratización hace accesibles tanto los datos como las herramientas necesarias para su explotación a usuarios con un perfil que podría ser no técnico o no especializado, y sin requerir la intervención directa de usuarios técnicos o departamentos IT.
Así pues, la modelización por componentes brinda la oportunidad de democratizar los procesos de desarrollo de algoritmos y la explotación de los datos, puesto que pone a disposición de usuarios no expertos el uso de técnicas de analítica avanzada. Esto hace posible, por ejemplo, que los analistas de negocio sean capaces de realizar análisis relativamente sofisticados.
Adicionalmente, el aumento del volumen de datos, la reducción de costes de los sistemas de la información y el aumento de la capacidad computacional han propiciado un entorno favorable para la democratización. No obstante, esto ha generado un desafío en las empresas desde un punto de vista organizativo, lo que genera un debate en torno a la misma. Por tanto, es de gran importancia no solo considerar la ventaja competitiva que puede ofrecer la democratización, sino también tener consciencia de los riesgos asociados a la misma para poder medirlos y gestionarlos. A continuación, se exponen algunos de los principales riesgos asociados:
- Interpretaciones erróneas de los datos. La posibilidad de interpretaciones erróneas por parte de equipos no especializados podría resultar en una toma de decisiones incorrectas. Por tanto, podría estar incrementándose el riesgo de modelo.
- Riesgos en la seguridad, integridad y confidencialidad de los datos. Cuanto mayor sea el número de usuarios que tengan acceso a los datos, mayor será el riesgo de seguridad de los mismos. Ello también aumenta la complejidad de la integridad y confidencialidad de los datos.
- Duplicidad de los esfuerzos. Diferentes equipos podrían estar realizando la misma tarea por duplicado, lo que puede generar ineficiencias frente a un enfoque centralizado.
- Aplicaciones de algoritmos y modelos de forma erronea. Los usuarios deben tener un conocimiento intrínseco de las técnicas de análisis de datos facilitadas para poder hacer un uso adecuado y coherente de las mismas.
Para mitigar estos riesgos se puede proporcionar formación específica en materia de análisis de datos a los distintos usuarios, con el objetivo de que tengan un conocimiento suficiente para tomar decisiones basadas en datos32. De este modo, se dispondrá de las capacidades esenciales para comprender los datos, determinar el valor que se puede extraer de ellos, y analizar los mismos mediante la aplicación de los algoritmos y modelos adecuados en cada caso de uso, dando lugar a una gran ventaja competitiva.
Conclusiones
En los últimos años, se ha observado una tendencia clara hacia la automatización de los procesos relacionados con la aplicación de técnicas de analítica avanzada, la cual ha incentivado un cambio notorio en el enfoque de modelización tradicional empleado hasta ahora.
Este cambio de paradigma se ha materializado a través de la modelización por componentes, la cual permite automatizar de forma flexible el proceso de modelización mediante la separación de los distintos procesos de construcción de modelos en componentes que puedan ser ejecutados de forma modular e independiente.
De este modo, gracias a las ventajas que presenta el uso de este nuevo enfoque (mejora de la eficiencia, mejora de la usabilidad, escalabilidad, etc.), multitud de empresas y compañías de todos los tamaños y sectores están incorporando de forma sencilla el uso de estas técnicas en sus procesos, brindándoles la oportunidad de extraer un mayor valor de sus datos. No obstante, las empresas también deberán tener en consideración los distintos riesgos asociados a este enfoque, tanto desde el punto de vista de la ejecución del proceso de modelización como los derivados de los retos de la implantación. En todo caso, este interés incipiente por parte de las empresas está propiciando que cada vez sea mayor la oferta de soluciones disponibles, pudiendo encontrarse una amplia variedad tanto de librerías como de herramientas específicas.
La newsletter “Modelización por componentes" ya está disponible para su descarga en la web de la Cátedra tanto en español como en inglés.