New paradigms and their challenges in the construction of neural networks
The iDanae Chair (where iDanae stands for intelligence, data, analysis and strategy in Spanish) for Big Data and Analytics, created within the framework of a collaboration between the Polytechnic University of Madrid (UPM) and Management Solutions, has published its 3Q24 quarterly newsletter on the new paradigms and their challenges in the construction of neural networks
New paradigms and their challenges in the construction of neural networks
Introduction
Over the last few decades, the development of neural networks in the field of artificial intelligence has made them a very effective tool for solving complex problems. From the ability to classify images to translating languages and generating text, the use of these networks has shifted the paradigm of machine learning and adaptation. Behind every breakthrough in this field there is a carefully designed and trained neural network. But not all neural networks are the same. Their architecture, complexity and learning capabilities vary drastically, which influences not only their performance, but also the resources needed to implement them.
As the field has evolved, a variety of architectures have emerged to meet specific needs. From the beginnings of simple multilayer networks, to sophisticated convolutional networks, recurrent networks and the latest transformers models, each has a specific purpose and requires a tailored infrastructure. This includes elements such as processing power, storage, energy cost and the need for resource scalability, which means that each architecture has its own ecosystem.
This whitepaper explores the most relevant neural network architectures, understanding how they are structured, their components and functioning, and analyses new trends and technical challenges.
Evolution of neural networks and their architectures
Artificial neural networks (ANNs) have come a long way since their origin in the 1940s to become a central part of modern Artificial Intelligence (AI). The beginning of the field can be traced back to Warren McCulloch and Walter Pitts' proposal of a mathematical model designed to simulate the functioning of biological neurons, which laid the theoretical foundation for the development of ANNs. In the following years, rules were introduced, such as Hebb's rule, or other discoveries such as the Perceptron, developed by Frank Rosenblatt in 1958 [2]. This became one of the first practical neural network models, capable of classifying inputs into two categories [3]. However, the 1980s saw a first resurgence of AI, with the emergence of multilayer neural networks and the error backpropagation algorithm, which allowed networks to model highly complex nonlinear functions [4], as well as major advances in hardware (such as the Connection Machine).
A second resurgence of AI took place from 2010 onwards, driven by the rise of deep learning, new hardware evolutions (such as clusters with GPU-like accelerators), and the release of free frameworks (e.g. TensorFlow). Deep Neural Networks (DNN) made it possible to model complex hierarchical relationships thanks to advances in computational power and the availability of large datasets. Models such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) revolutionised computer vision and natural language processing.
Today, ANNs continue to evolve, with the development of advanced models such as Generative Adversarial Networks (GANs) and Transformers. The latter have transformed natural language processing and other key areas of artificial intelligence due to their ability to handle complex relationships and large volumes of data efficiently. In the future, continued growth is foreseen, consolidating the fundamental role of ANNs in the advancement of intelligent systems.
Basic principles of neural networks
Artificial Neural Networks (ANNs) represent one of the most revolutionary technologies in the field of artificial intelligence. In general terms, an ANN defines mathematical functions containing adjustable parameters. These parameters are adjusted from the values of training data or samples through a loss function optimisation process, conceptually analogous to linear regression. To understand how it works, it is useful to break down its key components:
- A neuron is the basic processing unit, equivalent to the biological neuron. Each neuron receives inputs, processes them through a mathematical function and generates an output. These inputs are weighted by numerical values called weights, which determine the importance of each input in the neuron's final decision. The weights are adjusted during training to optimise the performance of the model.
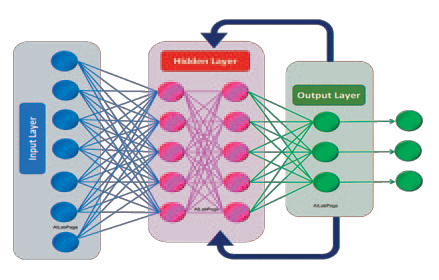
- The layers are made up of neurons. Each neuron in a layer is connected to all neurons in the next layer (or part of them, depending on the connectivity pattern - dense, convolutional, etc.), forming a network structure. Layers are divided into three types:
- The input layer receives the initial data, such as datafrom variables associated with each sample, or information from images or text (pre-processed and transformed through their representation in numericalvalues), which will be processed by the network.
- Hidden layers transform the data by applying non-linear functions, extracting features of increased complexity as the data go through the network structure. These layers allow the network to capturedeep patterns in the data.
- The output layer produces the outcome, which can bea classification (such as determining whether an image contains a cat or a dog) or a continuous value in regression problems.
- The activation function is part of each neuron and is the component that introduces non-linearity into the model so that the network can learn complex relationships. Some functions such as Sigmoid or Hyperbolic Tangent are useful in less profound networks or with specific tasks. ReLU, on the other hand, is used for its efficiency in deep networks.
- The loss function defines the target to be achieved during training and evaluates the performance of the model by measuring the error. The most common ones are the cross-entropy and the mean square error, used in classification and regression problems respectively [6]. In addition, this loss function can be modified by adding penalisations to establish regularisation procedures, which can be useful to make the network more generalisable.
- Backpropagation is the process of adjusting the weights of neural connections to minimise the error. It uses the gradient of the loss function to modify the weights based on the observed error between the desired output and the predicted output.
- Optimisation is the process of adjusting parameters toimprove model performance. Algorithms such as Stochastic Gradient Descent (SGD), Adam and RMSprop are very usefulfor finding the optimal values of the weights in the neural connections.
Depending on the arrangement of the network elements, the arrangement of the data flows, and the training mechanisms chosen, different types of network architectures can be constructed, resulting in different types of neural networks. The most common classical neural network architectures are the following (for a detailed description of each of them, see the sidebar in this document):
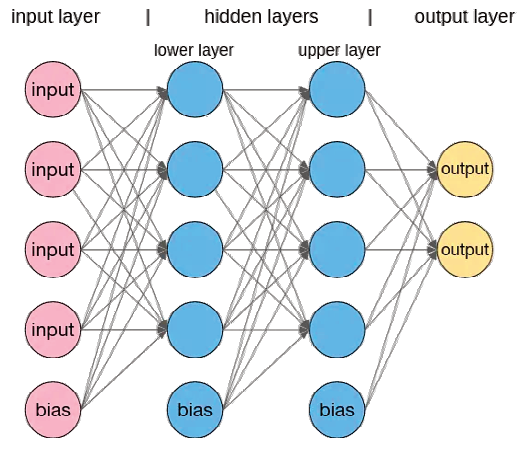
- Multi-layer perceptron (MLP): multiple layers of neurons (an input, intermediate layers and an output layer), where generally all neurons in one layer are connected to all neurons in the next layer.
- Convolutional Neural Networks (CNN): neural networks where, in the first part of the architecture, operations of combination or convolution of different data from a grid are carried out, applying filters to detect patterns.
- Recurrent Neural Networks (RNN): the architecture of these networks allows sequences to be analysed, since connections are established to previous layers (or to the input of the same layer) that allow cycles to be formed, thus maintaining information from previous events, which acts as a "memory" in the sequence.
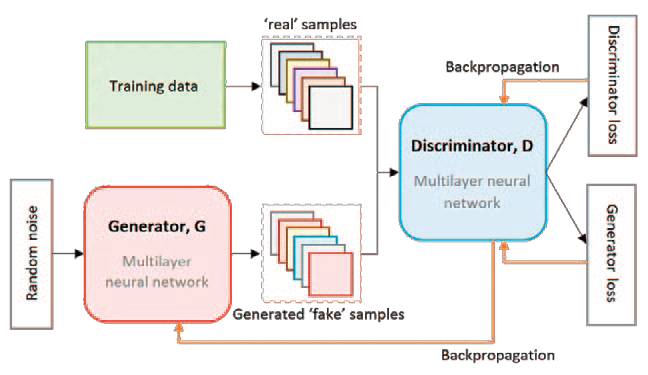
- Generative Adversarial Networks (GAN): is a network where training is performed from two components: a generator of synthetic data similar to the real training data, and a discriminator, which tries to classify the data between the previously created synthetic and real data. When the discriminator is not able to distinguish between real and synthetic data, the generator is already trained to generate new information.
However, new network structures have emerged, such as Transformers or Graph Neural Networks (GNNs), which have had a major impact on the field of generative artificial intelligence and the development of new artificial intelligence applications. These networks are described below.
Classical neural network architecturesMulti-layer perceptron (MLP)The Multi-Layer Perceptron (MLP) emerged as an evolution of the simple perceptron, overcoming its limitations and allowing the resolution of non-linearly separable problems, thanks to the inclusion of hidden layers. This architecture consists of multiple layers of neurons: an input layer, one or more hidden layers, and an output layer. Each connection between nodes has an associated weight, and each node (except the input nodes) has a non-linear activation function. This allows the network to learn more complex representations of the data, making it applicable to a variety of tasks, such as image classification, signal processing and tabular data analysis. Learning in an MLP is performed by a process called backpropagation, which iteratively adjusts the weights of the connections between neurons to minimise the loss function and, consequently, the error in predictions. This tuning capability makes the MLP extremely versatile and effective in a variety of applications. Practical applications
Convolutional Neural Networks (CNN)Convolutional Neural Networks (CNNs) are a type of architecture specially designed to process data that has a grid-like structure, such as images. Initially developed to address problems in computer vision, CNNs have proven to be extremely effective in tasks such as image recognition, object detection and semantic segmentation, among others. CNNs are a variant of MLPs, in which the pattern of connection between layers of neurons is modified, and are based on two key concepts
Practical applications
 Recurrent Neural Networks (RNN)Recurrent Neural Networks (RNNs) are specifically designed to process sequential data, where previous information in the sequence is crucial for the current prediction. Unlike traditional neural networks, RNNs have connections that form cycles in their architecture, allowing them to maintain a "state" or memory of previous events in the sequence. This makes them suitable for tasks where historical context is important, such as in natural language processing (NLP) and time series analysis.
Practical applications
Generative Adversarial Networks (GANs)Generative Adversarial Networks (GANs) are an innovative class of neural networks that have revolutionised the field of artificial intelligence, especially in the generation of synthetic data, such as images. GANs are notable for their ability to generate data that is virtually indistinguishable from real data. The core of GANs is based on a competitive training process between two neural networks: the generator and the discriminator.
Practical applications
 |
New Neural Network Architectures
Transformer architecture
Transformers have radically redefined the field of artificial intelligence, especially in the field of generative artificial intelligence, with a major impact on applications such as natural language processing (NLP) and, more recently, the generation of multimedia content (image, video, music, etc.). This architecture was proposed in 2017, and its main innovation is the self-attention mechanism, which allows processing sequences of data in parallel and efficiently, mitigating the limitations of previous models such as recurrent neural networks (RNN) or LSTMs. Transformers have been essential for the development of advanced models such as BERT and GPT, which have revolutionised text processing, machine translation, language generation, among other tasks.
Transformers possess several characteristics that have made them stand out in artificial intelligence:
- Parallelisation. Transformers are much faster in training than RNNs and LSTMs because they allow data streams to be processed in parallel, which takes better advantage of modern hardware architectures such as GPUs.
- Scalability. The ability of Transformers to scale to massive models, such as GPT-4 and GPT-5, has been crucial in creating neural networks with billions of parameters that can learn from large amounts of data. This is key to achieving high quality results in tasks such as language generation.
- Global Context. The self-attentional mechanism allows Transformers to understand long-term relationships in sequences, more effectively capturing the structure and meaning of language compared to RNN-based approaches, which have problems managing long-term dependencies.
As Transformers do not have sequential memory like RNNs, they use positional encodings to enable the model to understand the relative position of the tokens in the sequence. These encodings, which are added to the embeddings of the tokens, introduce information about the order of the elements in the sequence, allowing the model to deal not only with the individual data, but also with their sequence.
The NLP revolution: from BERT to GPT
Since the introduction of Transformers, the field of NLP has undergone an unprecedented revolution. Models such as BERT and GPT have taken natural language capabilities to new heights, facilitating everything from basic tasks such as machine translation to more advanced tasks such as text generation and sentiment analysis.
- BERT (Bidirectional Encoder Representations from Transformers). Introduced by Google, BERT has transformed the way networks understand context. Unlike unidirectional models, BERT uses a bidirectional approach, i.e., it considers both upstream and downstream context to understand the meaning of a word. This ability is essential for tasks such as sentiment analysis, where the meaning of aword may depend on what comes before or after it in the sentence. BERT has improved performance in many NLP tasks, such as text classification and entity recognition.
- GPT (Generative Pre-trained Transformer). The GPT family of models, developed by OpenAI, are known for their ability to generate high quality text. GPT is based on a unidirectional model, which means that it generates text token by token, predicting the next word from the previous context. This has enabled its use in applications such as chatbots, virtual assistants and recommender systems.
Practical applications
There are many applications being developed in industry. Among others, the following can be highlighted:
- Machine translation. Transformers have improved the quality of translations, allowing models such as Google's T5 (Text-to-Text Transfer Transformer) to understand the full meaning of sentences and translate them more accurately.
- Generation of Images from Text. Models such as DALL-E based on Transformers have shown extraordinary capabilities to generate images from textual descriptions, opening up new possibilities in the creation of multimedia content and AI-generated art.
- Medical applications. Transformers have also found applications in the analysis of large volumes of medical data. They are being used to analyse clinical texts and generate automatic summaries of biomedical research, improving the efficiency of data management in medicine.
- Automatic generation of documentation. The use of LLM for document generation is becoming increasingly important, as it improves the efficiency of business processes, reducing both documentation production times and possible operational errors (updating, consistency, etc.).
- Help with programming and code development. The use of this technology makes it possible, among other things, to correct bugs in the code of an application, to generate code from certain specifications, or to understand a developed code.
The continued evolution of Transformers ensures their central role in the future of artificial intelligence, not only in language processing, but in multiple areas of science and technology.
Graph Neural Networks (GNN)
Graph Neural Networks (GNN) are a type of architecture that extends the capabilities of traditional neural networks by working directly with structured data in the form of graphs. Graphs are structures composed of nodes (vertices) and links (edges) that represent relationships between entities. This architecture is especially useful for analysing data with complex and interdependent relationships, such as social networks, biological systems or even the analysis of molecules in chemistry and bioinformatics.
Structure and principles of GNNs
The fundamental structure of GNNs is based on the representation and processing of data in the form of graphs. Unlike traditional neural networks, which operate on tabular or sequential data (such as text or images), GNNs are designed to capture both information from individual nodes and connectivity information between them. GNNs achieve this by using an iterative process of aggregating information from neighbouring nodes to learn richer representations of graphs.
One of the key principles behind GNNs is the message-passing mechanism. At each layer of the network, a node's information is updated based on information from its neighbours. The goal is that, across multiple layers, each node achieves a representation that incorporates information not only about itself, but also about the local structure of the network, i.e. about the connected nodes and their relationships.
- Initialisation. Each node in the network starts with an initialrepresentation, which is usually based on the node's characteristics or attributes.
- Information Aggregation. In each iteration, nodes receiveinformation from their neighbouring nodes. This information aggregation process can be implemented by operations such as addition, averaging or concatenation ofthe feature vectors of adjacent nodes.
- Update. The new node representation is computed bycombining the previous representation with the aggregatedneighbour information. This allows the representation of each node to evolve to better capture its context within the network.
This process is repeated over several layers, allowing GNNs to learn rich representations that incorporate both the information of individual nodes and their surrounding structure.
As in CNNs (Convolutional Neural Networks), GNNs also use pooling or readout operations to obtain a final representation of the entire network. After several layers of processing, a pooling function can be applied to combine the information from all nodes into a single representation that summarises the entire network. This is particularly useful for tasks where the goal is to classify an entire graph, such as molecular property prediction in bioinformatics.
Practical applications
The field of application of Graph Neural Networks is wide and diverse, as graphs are a natural representation for many types of data. Some of the most prominent applications include:
- Social Network Analysis. Social networks can be modelled as graphs, where the users are nodes and the relationships between them are the edges. GNNs are used for tasks such as:
- Community detection. Identify highly interconnected sub-groups of users within a network.
- Link prediction. Anticipate future connections between users based on existing patterns.
- Influence detection. Determine which users have disproportionate influence within the network.
- Bioinformatics. GNNs have proven to be valuable tools for analysing biological and molecular networks. Molecules and proteins can be represented as graphs, where atoms are nodes and chemical bonds are edges. Some of the applications include:
- Prediction of molecular properties. GNNs have been used to predict properties of chemical compounds, such as biological activity or toxicity, which are essential in drug design.
- Protein-protein interaction. In biology, protein-protein interactions can also be modelled as graphs. GNNs make it possible to study how proteins interact with each other and predict behaviours based on these interactions.
- Recommender systems. Commercial platforms for audiovisual products or content can model their users and products as graphs, where edges represent interactions (such as a purchase or viewing). GNNs allow for improved recommender systems by capturing deeper relationships between users and products, based not only on direct interactions, but also on secondary relationships within the graph of users and products.
- Knowledge Modelling. In artificial intelligence systems, knowledge bases can also be represented as graphs, where entities (such as concepts or objects) are nodes and the relationships between them are edges. GNNs are used for tasks such as logical reasoning and inference on data in these graphs, improving the ability of systems to learn complex relationships between concepts and generate more accurate inferences.
In short, GNNs are a revolutionary breakthrough in artificial intelligence, providing a robust approach to working with unstructured data and complex relationships. Their ability to model networks and graphs has opened new possibilities in fields such as social networks, bioinformatics, and recommendation, where the underlying structure of data is critical for analysis.
Self-attention mechanism and how it worksThe architecture of Transformers consists of encoder and decoder blocks, where the encoder receives the input and the decoder generates the output, although some designs only include one of these two blocks. However, the core of their success lies in their approach to self-attention.
The process consists of calculating the similarity between the query and the keys using the scalar product, determining which elements of the sequence are most important for the current token. This produces an attention score, which is applied to the values to obtain a weighted representation of the sequence. A key feature of the self-attention mechanism is the use of Multi-Head Attention, which allows the network to learn multiple semantic relationships simultaneously between tokens. Each attention "head" is responsible for capturing different types of relationships in the data, such as the relationship between words at short or long distances in a text. This provides a global context that significantly improves the network's performance on tasks such as language understanding and text generation, as well as enabling parallel processing, which greatly reduces computational times. For example, in machine translation tasks, the model can capture the meaning of a word depending on the context of other words, even if they are far apart in the sentence. This approach outperforms RNNs and LSTMs, which struggle to maintain coherence over long sequences [27][30]. After the attention layer, Transformers use a feed-forward network to process token representations. Each token passes through a fully connected dense network that introduces non-linear complexity to the model. Between the attention and feed-forward layers, a normalisation layer is added to stabilise the training and help control the propagation of gradients, preventing them from amplifying or disappearing, a common problem in deep networks. 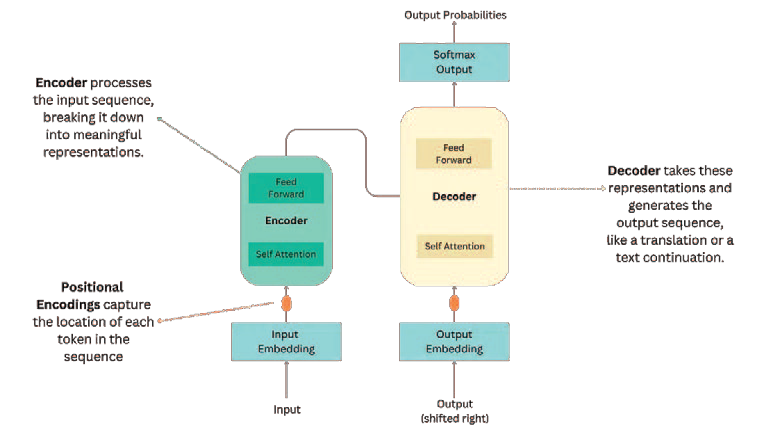 |
Current and Future Challenges of Neural Network Architectures
The advance of neural networks has driven huge developments in artificial intelligence. However, the future of these technologies also comes with key challenges, including scalability and efficiency, interpretability and explainability, privacy and security, and ethics. These problems need solutions both in terms of technical research and practical implementation to sustain their growth and acceptance.
Scalability and efficiency
With the massive growth of neural models, scalability and efficiency have become priority issues. Models such as GPT-4 or BERT, which have billions of parameters, require advanced infrastructures, resulting in high computational costs and considerable energy consumption.
Challenges in training large-scale models
- Exponential parameter growth: As models grow, the resource requirements increase significantly. Current models such as GPT-4, with over a trillion parameters, require weeks of training on large GPU or TPU clusters, incurring huge energy consumption and financial costs [36]. According to estimates, training these models can have a significant carbon footprint.
- Storage and training speed: As models increase in size, so does the amount of data they need to process, which slows down training and creates bottlenecks in storage and data processing systems. To mitigate these problems, advances include different parallel processing techniques such as model parallelism (splitting model layers across multiple machines) and pipeline parallelism (simultaneous training of different parts of the model, each processing different fragments of the dataset).
Efficiency in the use of computing resources.
As neural networks grow and become more complex, efficiency in the use of computational resources becomes a critical challenge. There are several techniques and approaches to address this problem:
- Reducing complexity through model compression techniques: Methods such as quantization, pruning and distillation make it possible to reduce the number of parameters and operations required by a neural network without losing too much precision. Quantization, for example, converts network weights into lower precision formats (e.g., from 32 bits to 8 bits), reducing memory usage and improving computational efficiency. Pruning eliminates unnecessary connections and neurons, while distillation allows smaller, more efficient networks to be trained from larger networks.
- Optimised algorithms for specialised hardware: To improve efficiency, many companies and institutions are developing specialised hardware for neural networks, such as TPUs (Tensor Processing Units) and dedicated chips. These chips allow the mathematical operations underlying network training to be performed much more efficiently than traditional CPUs or GPUs [8]. A key aspect of achieving high efficiency is to minimise data movement. One of the most effective ways to achieve this is to reuse each data read from memory in many consecutive operations.
- In addition, there are efforts in algorithmic optimisation, such as the use of more efficient matrix operations, distributed approaches to training, or efficient use of memory.
- In addition, hyperparameter search strategies and optimal configuration of the network architecture can be considered. It has been observed that an incorrect configuration of the training hyperparameters can consume up to 5 times more energy than the optimal configuration. Therefore, setting the correct hyperparameters can lead to greater efficiency in the training and use of the model. Likewise, the application of Neural Architecture Search (NAS) strategies to make the network architecture more efficient, as well as improve its energy efficiency.
- Edge AI: For applications that require real-time processing and without constant access to large data centres, it has become essential to perform inference (prediction) on local devices such as mobile phones or IoT devices. These devices often have limited computational and memory capabilities, so compressed versions of the models (such as in the case of lightweight networks like MobileNet and EfficientNet) are used to ensure that the process is fast and efficient without sacrificing too much accuracy.
Projects and future developments
- Optimisation of computational resources is one of the main projects. New algorithms and specialised hardware are being developed to improve the energy and computational efficiency of large models. Methods such as quantization and pruning reduce the number of parameters and speed up processing by eliminating unnecessary neurons and connections without sacrificing accuracy.
- One of the most promising developments to improve scalability is Federated Learning. It consists of training models locally on individual devices and then combining them into a larger one.
- Another very promising approach is to redefine neural networks in such a way that non-linear behaviour is achieved from a linear model by selecting a different subset of the linear model for each sample. Because of the linearity of the model, it is possible to easily combine different copies of a model trained on different data sets. This allows incremental retraining (even in federated learning), processing only new samples and without forgetting previously acquired knowledge.
Interpretability and explainability
In critical applications such as medicine or finance, it is essential that neural networks not only provide accurate predictions, but also explain how they arrived at those decisions. Interpretability is fundamental to building confidence in models, especially in systems that require sensitive decision-making.
Methods for understanding the behaviour of complex networks
Neural networks are complex systems and their behaviour looks like a black box. To understand how a neural network processes information, researchers use visualisation techniques that show which parts of an input activate certain neurons.
On the other hand, techniques such as SHAP and LIME are being used to make the results of neural networks more understandable. SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) are methods that help break down complex predictions into simpler features, showing how each feature affects the final model output.
Applications in sensitive areas such as medicine or finance
In medicine or finance, it is crucial that models are explainable. Diagnostic systems based on neural networks, which are used to identify diseases such as cancer or assess creditworthiness, must be able to justify their predictions. Graph neural networks (GNNs) are being used to identify interactions, where explainability allows for a better understanding of the relationships between different nodes in a network.
A traditional alternative to achieve good interpretability is to use easy-to-understand systems such as linear regression, decision trees or Bayesian networks. However, they are generally insufficient for very complex problems. The aforementioned system, being based on a globally linear model, also generates an equivalent linear model for each sample, which implicitly provides excellent interpretability.
Privacy and Security
With the growing use of neural networks in various applications, one of the most important challenges is to ensure data privacy and the security of the predictions generated by the models. The handling of sensitive data and the responsibility to prevent models from revealing unwanted information are key areas of current research.
Threats such as adversarial attacks
One of the biggest risks associated with advanced models is that they could generate harmful or unsafe content. For example, if a language model such as GPT is exposed to sensitive or malicious data, it could generate unwanted responses, such as explaining how to make a nuclear bomb or engaging in illicit activities. To address these threats, several options are implemented:
- Content filters and controlled training that evaluate the output generated by the network before delivering it to the user. These filters are designed to detect and block potentially dangerous content. In addition, during the training process, curated datasets are used that exclude dangerous or illegal information, reducing the likelihood that the model will learn such content.
Adversarial attacks manipulate inputs to models to trick them into generating incorrect or harmful outputs. To protect models against these attacks, techniques such as defensive distillation and adversarial training are used to strengthen the robustness of the model against malicious inputs. These techniques are fundamental to ensure the security of AI applications in critical fields such as defence and healthcare.
Privacy preservation techniques: Federated Learning, Differential Privacy
As neural networks are trained on massive datasets, it is essential to ensure that sensitive or private information is not exposed, especially in fields such as medicine, finance or education. To address this challenge, several techniques have been developed to preserve data privacy without sacrificing model quality:
- Federated Learning. As noted, this approach distributes the training process locally, which can be done even on individual devices (mobile or IoT devices). The data never leaves the user's device; instead, a model is trained locally and then only the model weights are shared with a central server, where they are combined to improve the overall model.
- Differential Privacy. This is another key approach to privacy preservation, which ensures that the outputs of a model do not reveal specific information about individuals in the training data. Mathematical noise is added to the data during training to ensure that the results cannot be traced back to specific individuals, thus protecting privacy. This is crucial to prevent models from exposing sensitive user or patient data.
- Synthetic Data. Generative adversarial networks can be used to produce synthetic data with identical distribution to the original data, so that the generated synthetic data can be used to train neural networks, without compromising the privacy of the original data.
Ethics
The development and use of these techniques must be carried out with an ethical dimension:
- On the one hand, during the training phase there are aspects that may introduce biases in the models. For example, the data used for training must be analysed to understand whether any preprocessing is required to avoid bias (by race, gender, etc.). When using historical data, undesirable patterns may be perpetuated, and this can be avoided by modifying the training samples, although this may impact the predictive power of the model.
- On the other hand, there is a need to ensure responsible and safe use of artificial intelligence (e.g. by limiting its use in recreational activities, reducing unnecessary use of models that have an excessive environmental impact, avoiding malicious uses such as the production of fake news that appear to be true, or ensuring that companies' confidentiality codes and frameworks are respected).
Conclusions
Neural networks have proven to be fundamental to the development of advanced artificial intelligence solutions, constantly evolving to address increasingly complex challenges. This whitepaper explores several key architectures and trends that are shaping the direction of this technology.
Classical architectures such as Multi-Layer Perceptron (MLP), Convolutional Networks (CNN) and Recurrent Networks (RNN) continue to be relevant in multiple applications, from image classification to time series analysis. However, emerging architectures such as Transformers and Graph Neural Networks (GNN) have revolutionised fields such as natural language processing and structured data analysis, respectively, offering new capabilities in terms of efficiency, scalability and handling of complex data.
At the same time, challenges such as scalability, interpretability and privacy remain critical points to be solved. Model compression techniques, the use of specialised hardware and federated learning emerge as promising solutions to cope with the increasing demand for computational resources and to ensure data security and privacy. In addition, the interpretability of neural networks is becoming increasingly important in sensitive applications, where it is crucial to understand how and why certain predictions are generated.
In summary, neural networks continue to evolve at great speed, with significant advances in their architecture and applications. The future of these technologies is marked by their ability to scale, improve efficiency and ensure transparency and security in their applications. This promises to continue to transform industries and redefine the future of artificial intelligence.
The newsletter is now available for download on the Chair's website in both in Spanish and English.