Cátedra iDanae: Los ecosistemas Open Source
La Cátedra iDanae (inteligencia, datos, análisis y estrategia) en Big Data y Analytics, creada en el marco de colaboración de la Universidad Politécnica de Madrid (UPM) y Management Solutions, publica su newsletter trimestral correspondiente al 1T22 sobre los ecosistemas Open Source
Cátedra iDanae: Los ecosistemas Open Source
Introducción
La evolución desde una sociedad de la información hacia una sociedad del conocimiento está estrechamente relacionada con el desarrollo de los sistemas de información y las nuevas tecnologías. Dichos sistemas se basan en información, que se ha convertido en un instrumento del desarrollo humano para identificar, producir, procesar, transformar, difundir y utilizar el conocimiento1. El desarrollo de las herramientas empresariales para llevar a cabo estos procesos ha experimentado una gran transformación. De hecho, ya a principios del siglo XXI la Comisión Europea trata en algunos informes el concepto de ecosistema digital como una evolución de los entornos colaborativos.
Por tanto, uno de los elementos clave para la extracción y tratamiento de la información es el desarrollo de software eficiente, que esté disponible en un entorno tecnológico adecuado para su uso. Esto ha provocado una evolución natural desde sistemas de información tradicionales a los denominados ecosistemas Open Source.
En efecto, en los últimos años se viene observando una creciente adopción del Open Source por parte de las empresas: en el cuarto trimestre de 2021, la plataforma de colaboración Open Source GitHub informó de que dispone de más de 16 millones de nuevos usuarios con respecto al año anterior, con más de 73 millones de desarrolladores activos, lo que supone un crecimiento del 30% respecto a 2020. Asimismo, GitHub Enterprise (la versión orientada a empresas de GitHub) es utilizada por 84 de las 100 empresas con mayores ingresos brutos de EEUU.
En el caso particular de Europa, el ecosistema Open Source se está introduciendo cada vez más en el tejido empresarial. Según un informe de Red Hat, el 75% de las empresas emplean software Open Source en ámbitos clave de su infraestructura, como seguridad (52%), herramientas cloud (51%), bases de datos (49%) y análisis y big data (47%).
El open source aporta además una perspectiva dinámica en el proceso de desarrollo de software, lo que permite que se realicen progresos más rápidos en la generación del código. Esta perspectiva se consigue a través de la comunidad, donde el desarrollo colaborativo y la publicación de proyectos permite distintas bifurcaciones en la evolución de un programa, lo que redunda en un entorno de desarrollo competitivo.
El objetivo de la presente newsletter es ilustrar los conceptos principales del ámbito Open Source, y mostrar el estado del arte de los ecosistemas tecnológicos cuyos componentes de software tienen licencias de código abierto y de software libre.
Concepto e historia
La expresión Open Source (o código abierto) hace referencia originalmente al código diseñado para ser accesible de forma gratuita por todo tipo de usuarios. De este modo, cualquier persona es capaz de visualizar, transformar y distribuir el código sin restricciones.
El desarrollo del software Open Source se produce de manera descentralizada y colaborativa: cualquier grupo de trabajo puede aportar un desarrollo en una parte de un código, de forma que la revisión entre distintos miembros de los equipos y la producción por parte de la comunidad se convierten en factores relevantes. Esto dota al proceso de generación de software de un carácter más económico y flexible que algunas soluciones propietarias.
El software Open Source pone su código fuente a disposición de los usuarios finales de forma legal a través de una licencia específica. Normalmente el software se considera Open Source si cumple con las siguientes condiciones:
- Está disponible en forma de código fuente sin coste adicional, lo cual significa que los usuarios pueden visualizar el código del software y hacer todos los cambios que deseen.
El código fuente se puede reutilizar en un software nuevo, así que cualquier persona puede usar el código fuente para desarrollar su propio programa y distribuirlo.
El hecho de ser Open Source no significa que el software ejecutable se distribuya sin coste. No obstante, sí que significa que su código fuente está disponible sin coste. Hay dos conceptos relacionados con el paradigma Open Source: el software libre y el software Open Source. El primero hace referencia a un concepto ético según el cual los usuarios de software libre deben tener siempre el derecho de ejecutar, analizar, modificar y distribuir el software en cuestión. Además, cualquier distribución que se haga de alguna modificación de software libre debe ser también software libre. El segundo concepto hace referencia a un aspecto pragmático y fundamenta su existencia en la ineficacia del código privativo para resolver ciertos problemas. Entre las consideraciones del software Open Source no se encuentra la libertad del usuario para usar o modificar ese código, pero sí que el código fuente esté disponible para el usuario. Así, cualquier modificación de un software Open Source no tiene necesariamente que ser Open Source ni garantizar que su código fuente esté disponible para los usuarios.
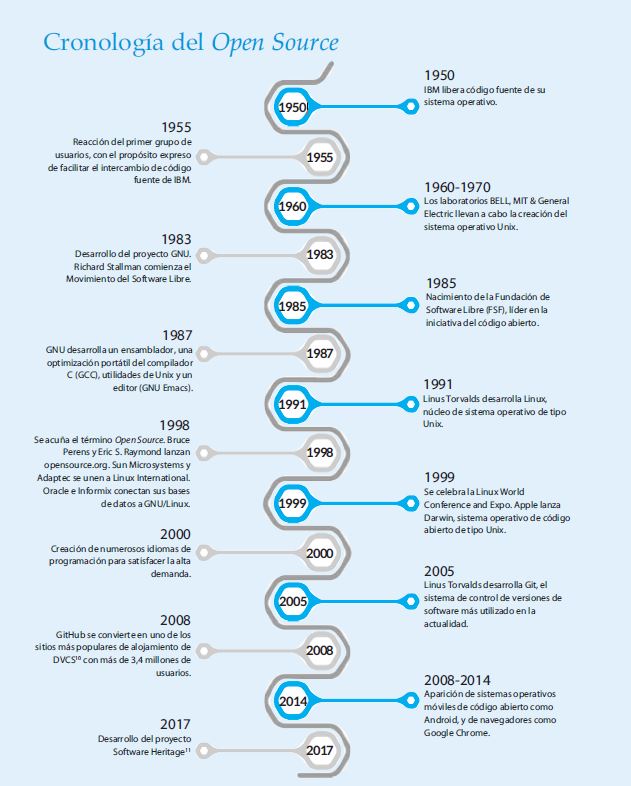
El origen del paradigma Open Source se remonta a las décadas de 1950 y 1960, cuando los investigadores que llevaron a cabo los primeros desarrollos de las tecnologías relativas a Internet y los protocolos de redes de telecomunicaciones dependían de un entorno de investigación colaborativo y abierto. La red Advanced Research Projects Agency Network (ARPANET), que a la postre se convertiría en la base para el Internet actual, incentivó la revisión colaborativa y el proceso de retroalimentación, lo que permitió el gran avance que se dio en esa época.
Los grupos de usuarios compartían el código fuente, que podía utilizarse como base para nuevos desarrollos, y se mantenían conversaciones a través de foros donde se desarrollaban estándares para la colaboración y las comunicaciones abiertas. A principios de la década de 1990, cuando se originó Internet, todos estos valores y buenas prácticas que formaban parte de esta cultura abierta ya estaban asentadas en el ámbito de la producción del software.
Las ventajas de este enfoque hicieron que el desarrollo de código abierto se convirtiese en una forma de trabajo que trascendió la producción del software: muchos modelos de negocio en distintos sectores productivos adoptaron sus valores y su modelo de producción descentralizada para encontrar nuevos modos de solucionar problemas.
Hoy en día, el movimiento Open Source se ha convertido en uno de los pilares fundamentales de la transformación digital, tanto en las pequeñas como en las grandes empresas. Tesla, OpenAI, Facebook o Google son algunas de las empresas que lideran la innovación con Open Source. Gigantes tecnológicos como Apple o Microsoft ya ofrecen software compatible con Linux.
Uno de los mayores proyectos de código abierto es la Software Heritage Inititative, cuya misión es reunir en un mismo lugar todo el código fuente del mundo para que cualquiera pueda explorarlo de manera sencilla. Se llevó a cabo en el Inria (Institut National de Recherche en Informatique et en automatique) bajo el amparo de la UNESCO, con la intención de preservar el conocimiento del código fuente y hacerlo ampliamente disponible a través de una gran biblioteca digital. La UNESCO declara en 2017 a este software patrimonio cultural de la humanidad, que debe preservarse como la música o la literatura. A su financiación contribuyen instituciones públicas como el Ministerio de Innovación de Francia y varias universidades, pero también bancos como Société Générale o empresas como Microsoft, Google, Intel o Huawei.
Los ecosistemas Open Source
Definición y funcionamiento
Un ecosistema de software es un espacio de trabajo en el que conviven una serie de herramientas que, acompañadas de unas buenas prácticas, permiten a un equipo de desarrollo realizar un proyecto donde se involucra un software bajo una metodología de trabajo. Con el desarrollo de nuevas aplicaciones y el uso del software de manera abierta, muchas empresas han logrado crear un ecosistema Open Source, una comunidad con multitud de desarrolladores que abogan por el código abierto y que desarrollan sus proyectos de manera dedicada mientras comparten su progreso con otros contribuidores externos a la compañía. Un ejemplo es el ecosistema creado por Intel “01.org”, donde los desarrolladores de Intel comparten los proyectos que mantienen y desarrollan.
No obstante, no todas las empresas son partidarias de compartir su código. Según sea la finalidad del código se puede distinguir entre software de código abierto y de código cerrado:
- El código abierto es aquel cuyo código fuente está disponible públicamente, y que también permite su uso, modificación y redistribución de forma totalmente libre.
- El código cerrado, al contrario, es aquel que no permite el acceso a su código fuente, lo que imposibilita el análisis de sus funcionalidades a través del código. En este caso, la garantía sobre el tratamiento de datos personales o la seguridad del software, entre otros, se delega en el propietario del código (bien sea una persona física o jurídica). Del mismo modo, se impide su modificación y posterior distribución.
La distribución de software, ya sea de forma abierta o cerrada, se realiza mediante el uso de diferentes licencias de software, que constituyen un contrato entre el distribuidor del código y los usuarios finales del mismo. Estas licencias establecen los criterios bajo los cuales los usuarios pueden disponer del software y con qué condiciones pueden redistribuir o modificar el código, en el caso de que la licencia lo permita.
En términos generales, se pueden distinguir dos tipos principales de licencia:
Licencias de código abierto:
- Permisivas: permiten modificar y distribuir el código original sin ninguna limitación.
- Robustas: limitan el tipo de licencia que se puede conceder al de software derivado, aquel basado en la modificación del código original. Dentro de este grupo, se pueden encontrar dos tipos:
- Fuertes: obligan a mantener la misma licencia del código original en todas las subsiguientes modificaciones realizadas sobre el mismo.
- Débiles: obligan a mantener la misma licencia del código original sobre modificaciones de código, pero permiten libertad en el caso de obras derivadas.
Licencias de código cerrado: estas licencias establecen las limitaciones sobre el uso, modificación y distribución del código según el criterio que establezca su propietario. Por norma general suelen limitar la modificación y distribución, y establecen límites sobre el número de copias que pueden ser utilizadas y sobre los fines de su utilización.
De entre las licencias más utilizadas se pueden destacar las siguientes:
- GNU GPL (licencia abierta robusta fuerte): esta licencia permite usar y modificar el software libremente. También permite distribuir nuevas versiones del software siempre que se haga bajo esta misma licencia. Algunos ejemplos de software Open Source que usan esta licencia son Bash y GIMP.
- MIT (licencia abierta permisiva): esta licencia permite usar y modificar el software libremente. Además, permite distribuir nuevas versiones del software bajo cualquier otra licencia incluyendo licencias de código cerrado.
- Apache License (licencia abierta permisiva): esta licencia permite usar y modificar el software libremente siempre que se conserven los derechos de autor y el descargo de responsabilidad, pero no requiere hacer disponible el código fuente en versiones desarrolladas distribuidas. Algunos ejemplos de software Open Source que usan esta licencia son Android y Swift.
Tipologías de ecosistemas
A continuación, se exponen los principales conceptos y distintos ejemplos de algunos de los actores del marco tecnológico que conforman los ecosistemas de software en diferentes ámbitos del desarrollo de software.
Sistemas operativos
Dentro de los ecosistemas Open Source destaca Linux, el núcleo de un sistema operativo desarrollado por el programador finlandés Linus Torvalds. Generalmente, en la actualidad Linux se entiende como un conjunto de sistemas operativos Open Source que han llegado a convertirse en uno de los más populares del mercado. Son los más utilizados en servidores web, en súper ordenadores e incluso en el CERN. El desarrollo de estos sistemas operativos es uno de los ejemplos más prominentes de software libre: todo su código fuente puede ser utilizado, modificado y redistribuido libremente por cualquier persona, empresa o institución, bajo los términos de la Licencia Pública General de GNU.
La principal ventaja que tiene Linux frente a otros sistemas operativos es que se lanzó bajo una licencia de código abierto robusta fuerte, publicando su código fuente, y permitiendo su modificación y distribución, pero siempre manteniendo la licencia original. Sobre el núcleo de Linux existen distribuciones que cuentan con soporte comercial como Fedora (RedHat), openSUSE (SUSE) y Ubuntu (Canonical Ltd), y también distribuciones mantenidas por la propia comunidad como Debian.
Además, Linux ofrece una alta modularidad (es decir, que sobre su núcleo se van montando diferentes módulos o partes del sistema operativo, como la interfaz gráfica o el sistema de archivos, sin que el núcleo dependa de un único módulo en concreto, siendo así personalizable). Cada uno de los módulos se encuentra separado de forma independiente, de forma que, si alguno falla, no afecta a los otros ni al núcleo, lo que hace a estos sistemas operativos ser tolerantes a fallos.
Herramientas de Entorno de Desarrollo Integrado (Integrated Development Environment o IDE)
Un entorno de desarrollo integrado (IDE) es una aplicación informática que facilita al desarrollador la tarea del desarrollo de software a través de diversas funcionalidades. Generalmente, un IDE cuenta con un editor de código fuente, un compilador del software desarrollado y un depurador para la obtención de errores. Los IDE permiten que los desarrolladores comiencen a programar aplicaciones nuevas con rapidez, ya que no necesitan establecer ni integrar manualmente varias herramientas como parte del proceso de configuración.
Hay varios casos prácticos comerciales y técnicos diferentes para los IDE, lo que desemboca en una amplia variedad de opciones propietarias y Open Source de estos entornos en el mercado. En general, hay una serie de características importantes que diferencian a los IDE, como la cantidad de lenguajes que soportan, los sistemas operativos compatibles, los plugins y extensiones que contenga, o el impacto en el rendimiento del sistema. Algunos de los IDEs más populares del mercado son Eclipse, PyCharm, IntelliJ o XCode.
Desarrollo web FrontEnd
En cuanto al desarrollo del FrontEnd (mecanismo para el desarrollo web que trabaja la interfaz de interacción del usuario), existen multitud de herramientas Open Source disponibles en el mercado, basadas mayoritariamente en el lenguaje de programación JavaScript. Se trata de un lenguaje potente que interactúa de manera sencilla con HTML y CSS, que permite al desarrollador agregar funciones dinámicas a una página web.
Un framework de JavaScript destacado es AngularJS. Mantenido por Google, se utiliza para crear y mantener aplicaciones web de una sola página. Su objetivo es aumentar las aplicaciones basadas en navegador con capacidad de Modelo Vista Controlador (MVC), en un esfuerzo para hacer que el desarrollo y las pruebas sean más fáciles. Otros frameworks populares en la industria son React o Vue.
Desarrollo BackEnd
Entre la variedad de lenguajes para desarrollo BackEnd (parte del desarrollo web que se encarga de que toda la lógica de una página web funcione) existentes en la actualidad destaca Python, lenguaje interpretado y multi-paradigma con el que se puede crear cualquier tipo de programa, e incluye librerías y funciones que garantizan una amplia versatilidad. Además, dispone de múltiples APIs para facilitar el uso de otros lenguajes, como Spark y su API Pyspark, y de diversas herramientas como Mongo y su API Pymongo. Otro ejemplo es Java, lenguaje de programación orientado a objetos, con el que se puede desarrollar código una única vez, y después ejecutarlo en cualquier tipo de dispositivo. Estos dos lenguajes son, según el índice TIOBE, el primer y el tercer lenguaje de programación más usados del mundo. Este amplio uso, debido en parte a su fácil accesibilidad por ser software Open Source, resulta extremadamente útil para desarrollar software, pues muchos de los problemas a los que hay que enfrentarse están ya resueltos por otros desarrolladores.
Bases de datos
Una base de datos es una colección de datos persistentes que se utiliza por sistemas y aplicaciones. Las bases de datos son indispensables para cualquier aplicación web, y se pueden diferenciar entre relacionales y no relacionales. Las relacionales se basan en la organización de la información en trozos pequeños, que se relacionan entre ellos mediante una serie de identificadores. En cambio, las no relacionales no tienen un identificador que sirva de relación entre un conjunto de datos y otros.
Algunos ejemplos de sistemas de gestión de bases de datos relacionales de código abierto muy populares en el mercado son MySQL, PostgreSQL o MariaDB. Son sistemas de gestión de base de datos que hacen uso de múltiples tablas para el almacenamiento y organización de la información. En cuanto a las no relacionales, cabe destacar MongoDB y Cassandra, bases de datos que no almacenan datos en registros, sino en forma de clave-valor.
Control de versionado de código
Git es un software de control de versiones diseñado por Linus Torvalds, pensando en la eficiencia, la confiabilidad y compatibilidad del mantenimiento de versiones de aplicaciones cuando estas tienen un gran número de archivos de código fuente.
Dado que el código está disponible para cualquier persona que desee consultarlo, cualquier usuario o desarrollador puede sugerir mejoras y resolver fallos en cualquier momento. En este sentido, esta herramienta resulta clave dentro de los ecosistemas Open Source, ya que los repositorios de código permiten coordinar las distintas versiones que va desarrollando cada uno de los múltiples contribuyentes a un proyecto. Esto resulta fundamental cuando existen múltiples desarrolladores que trabajan de forma descentralizada.
Surge así el concepto de “fork” o bifurcación, que consiste en el desarrollo de un proyecto de software basado en un código fuente que ya existe, dando lugar a una ramificación de un proyecto padre en varios proyectos hijos, independientes entre sí, que pueden contar con objetivos y desarrolladores diferentes. Por ejemplo, Android, Debian y Ubuntu son bifurcaciones de software derivados de GNU Linux. Esto permite que se realicen progresos más rápidos en la generación del código, y que se consiga una dinámica competitiva, donde las ramas más eficientes pueden aprovecharse en la consecución del programa final.
Existen diferentes servicios de alojamiento de repositorios de Git, donde destaca GitHub, plataforma que permite a usuarios de todo el mundo colaborar, comentar y desarrollar código de forma conjunta; de ahí que se haya convertido en uno de los pilares principales de los ecosistemas Open Source. Dada la importancia de la distribución del código para su posterior modificación en el entorno Open Source para incluir mejoras o nuevas funcionalidades, GitHub permite que cualquier usuario registrado descargue código, lo modifique y proponga incorporar sus cambios al código original.
Esto ha hecho que GitHub crezca de forma vertiginosa desde su lanzamiento en 2008, pasando de contar con 46.000 repositorios, a 10 millones en 2013, llegando a ser comprada por Microsoft por 7.500 millones de dólares. La evolución de Microsoft le ha llevado a convertirse en una de las compañías con más desarrolladores contribuyendo al Open Source en GitHub.
Otra de las plataformas de control de versiones más popular es GitLab, que a pesar de su similitud con GitHub tiene algunas diferencias destacables. En principio, ambas plataformas se pueden instalar en un servidor propio. En el caso de GitHub, se requiere la versión Enterprise de pago, mientras que GitLab permite hospedar el programa en un servidor propio con la Community Edition gratuita. La estabilidad del servidor de la variante hospedada de GitLab es ligeramente peor que la de GitHub, por lo que puede resultar muy ventajosa la instalación en un servidor propio. Adicionalmente, GitLab ofrece integración continua gratuita de fábrica, factor del que GitHub carece.
Herramientas DevOps
Las herramientas DevOps se entienden como una filosofía de trabajo orientada a permitir un escalado de los proyectos más ágil y automatizado. Se emplean en todas las fases de desarrollo de software y son fundamentales para el desarrollo eficiente del mismo. Una de las herramientas DevOps más utilizada en la actualidad es Docker: una plataforma que sirve como contenedor de paquetes que incluye librerías, archivos y configuraciones, agilizando su implementación y haciendo posible una integración continua. Otro ejemplo de plataforma DevOps es Kubernetes, que permite automatizar operaciones de contenedores en Linux.
Ejemplo de desarrollo de un modelo Machine Learning basado en Open Source
El ciclo de vida de un modelo de Machine Learning se puede estructurar en distintas fases que requieren capacidades concretas, y donde las herramientas Open Source cobran una gran relevancia en muchos proyectos en la actualidad. Este ciclo de vida se puede conceptualizar en tres bloques principales: Dato, Desarrollo e Industrialización.
- El bloque del Dato es la primera fase de todo ciclo de vida de un proyecto de Machine Learning. En esta fase se definen las características del almacenamiento de la información que se va a emplear en el proyecto, así como la forma de ingesta de los datos. Para ello, existe una amplia variedad de ecosistemas Open Source que facilitan esta tarea. Por ejemplo, se puede destacar Pentaho, un software de Business Intelligence (BI) que proporciona la integración de datos, servicios OLAP, informes, paneles de información, extracción de datos, así como capacidades de extracción, transformación y carga de datos (ETL).
- El bloque de Desarrollo abarca múltiples fases que se van sucediendo entre sí para la generación de pipelines de creación de modelos. Una primera fase es la de recopilación y preparación de los datos. Para ello se puede emplear DVC, un sistema Open Source de control de versiones para proyectos de Machine Learning, diseñado para hacer que los modelos de Machine Learning se puedan compartir y reproducir. DVC permite manejar archivos grandes, conjuntos de datos, modelos y métricas, así como código. Para las posteriores fases de feature engineering y entrenamiento de modelos, existen multitud de librerías Open Source especializadas que permiten agilizar y optimizar estas tareas, como las disponibles en el lenguaje de programación Python (por ejemplo, Scikit-learn, que cuenta con algoritmos clásicos de Machine Learning para tareas de clasificación, regresión, clustering o reducción de dimensionalidad; entre otros, NumPy, SciPy o matplotlib). Existen librerías especializadas en Deep Learning como es el caso de Tensorflow o Pytorch que permiten ir construyendo por bloques la arquitectura de cada red neuronal. En la última fase de este bloque se encuentra la evaluación del modelo desarrollado donde MLflow, plataforma Open Source, permite administrar el ciclo de vida de Machine Learning, incluida la experimentación, la reproducibilidad, implementación y un registro de modelo central.
- Finalmente, se desarrolla el bloque de Industrialización: para poner en producción un modelo se puede optar por el empleo de un framework de alto nivel que permita el desarrollo rápido de plataformas web de manera segura y mantenible. Entre las múltiples opciones Open Source disponibles en el mercado, destaca el uso de Django y FastAPI. Tras la puesta en producción del modelo, es necesario establecer la forma de utilizar correctamente el modelo en función de las necesidades del proyecto. De igual manera, es necesario el empleo de una herramienta para la gestión de colas, como RabbitMQ o Apache Kafka. Finalmente, de cara a realizar la monitorización del modelo en producción, se utilizan datos actualizados para analizar una posible degradación del modelo. Para ello, una de las plataformas Open Source más empleadas es MLFlow, mencionada en la fase de desarrollo.
La comunidad Open Source
La comunidad Open Source es un concepto muy amplio que incluye tanto a los usuarios de software libre como a sus desarrolladores. El principio básico en el que se asienta cualquier comunidad Open Source es el de compartir todo el código fuente tanto con desarrolladores como con usuarios finales. La forma de articular y asegurar la disponibilidad de dicho código fuente, y en general del carácter Open Source de un proyecto, se consigue mediante licencias Open Source.
Uno de los aspectos fundamentales de una comunidad en general, y en particular de una comunidad Open Source, es cómo se coordinan las contribuciones de sus miembros. Generalmente las comunidades Open Source son organizaciones descentralizadas y poco jerárquicas. Los proyectos se van construyendo con aportaciones de los diversos desarrolladores, que antes de añadirse a cada versión del proyecto son revisados por otros colaboradores de la comunidad.
Otra consideración importante sobre las comunidades Open Source es la reciente nueva función que cumplen como herramienta para conectar a futuros empleados y empleadores. Muchas grandes empresas tecnológicas emplean estas comunidades para buscar posibles trabajadores y viceversa. Esto se suele realizar a través del planteamiento de problemas relacionados con el desarrollo de proyectos Open Source (posiblemente de entre los que estén realizando internamente). De esta forma, disponen de todos los recursos de la comunidad Open Source, y aquellos desarrolladores que contribuyan a resolverlos de forma significativa pueden ser posibles candidatos a ofertas de trabajo. En los últimos años la comunidad Open Source se está convirtiendo en un recurso fundamental para las grandes empresas tecnológicas. De hecho, cada vez más cantidad de financiación y de código Open Source es proporcionado por estas empresas.
En el ámbito universitario, el movimiento Open Source ha ganado tracción gracias a la comunidad universitaria, creándose gran cantidad de proyectos de esta tipología. Existen múltiples repositorios en los que se agrupan los proyectos Open Source desarrollados actualmente por distintas universidades y grupos de investigación, como por ejemplo el MIT o la Universidad de Harvard. Ello facilita la difusión de los proyectos y la colaboración en los mismos.
Una breve historia de la comunidad Open Source
A lo largo de la historia la comunidad Open Source ha ido cambiando según la sociedad introducía los ordenadores en su desarrollo.
En 1983, cuando el movimiento de software libre daba sus primeros pasos, la comunidad estaba formada principalmente por académicos y profesionales del mundo de la programación, aunque dichos miembros de la comunidad ya llevaban desde los años 50 aplicando los principios del movimiento Open Source. Sin embargo, prácticamente ninguna empresa que se dedicaba a la producción de software lo hacía bajo la filosofía Open Source.
El desarrollo de la comunidad del software libre empezó a crecer de forma exponencial durante los años 90 paralelamente al uso de los ordenadores en el mundo empresarial y personal. Durante estos años no solo creció el número de miembros de la comunidad Open Source, sino que se ampliaron los tipos de miembros:
Se crearon o consolidaron grandes fundaciones sin ánimo de lucro dedicadas exclusivamente a fomentar la creación de software libre. Algunas de las más relevantes son la Apache Software Foundation (1999) y la Free Software Foundation (1985). Estas fundaciones tienen formas distintas de funcionar, pero persiguen el mismo objetivo: contribuir y fomentar el desarrollo del código Open Source.
La Apache Software Foundation (ASF) se dedica a desarrollar y dar soporte a proyectos de software bajo la denominación Apache. Se define como una comunidad descentralizada de desarrolladores que trabajan en diversos proyectos de código abierto, en los cuales el consenso entre los desarrolladores es necesario para determinar el futuro de cada proyecto. Si bien es cierto que existen líderes de cada proyecto, estos son elegidos por votación entre los propios desarrolladores del proyecto. Actualmente la ASF cuenta con más de 41.000 desarrolladores de código y casi 500.000 contribuidores de la comunidad que, a pesar de trabajar de forma descentralizada, se articulan en torno a unos códigos de conducta y buenas prácticas imprescindibles y comunes para formar parte de su comunidad de desarrolladores y contribuidores. Algunos de los proyectos que ha desarrollado y para los que da soporte son Apache HTTP Server (uno de los servidores web HTTP más utilizados), Cassandra (base de datos distribuida NoSQL).- Spark (framework de computación en cluster Open Source). Por otro lado, la Free Software Foundation centra sus esfuerzos en articular las medidas legales y organizativas necesarias para asegurar la supervivencia de la filosofía Open Source (en lugar del desarrollo de código Open Source).
- Surgieron nuevas empresas dedicadas exclusivamente al desarrollo y comercialización de software Open Source que encontraron la forma de monetizarlo. Un ejemplo es Red Hat (1993), que desarrolla software Open Source para empresas principalmente, e incluso compra software privado que después distribuye como Open Source.
Por otro lado, en el ámbito universitario se han continuado desarrollando múltiples proyectos Open Source. A continuación, se destacan algunos ejemplos:
- El MIT ha desarrollado una herramienta para evaluar el rendimiento de herramientas de computer vision en el ámbito biomédico. Esta herramienta cuenta con decenas de miles de imágenes y con herramientas estadísticas para la evaluación de aplicaciones para la detección de tumores usando diferentes modalidades de imagen médica. Propone un estándar para que la obtención de resultados entre diferentes grupos de investigación sea homogénea, lo que permite comparar los resultados sobre unas bases comunes. Tanto las imágenes como el código se encuentran disponibles en un repositorio de GitHub, y se insta a que los usuarios adapten y mejoren el código para su uso en otros proyectos.
- El proyecto AI Clinitian del Imperial College de Londres hace uso de técnicas de aprendizaje por refuerzo para modular el tratamiento intravenoso que reciben los pacientes que se encuentran en la UCI por casos de sepsis grave. En este caso, el código se encuentra disponible en GitLab, habiéndose publicado el proyecto en la revista Nature.
- La Universidad Carlos III de Madrid ha desarrollado el plugin deepImageJ para la herramienta de procesado de imágenes ImageJ. Esto permite a usuarios sin formación previa en Inteligencia Artificial (AI), como podría ser el personal sanitario, el uso de redes neuronales preentrenadas para distintas aplicaciones en microscopia, como la estimación de mapas de densidad o la segmentación automática de células.
Beneficios y riesgos asociados
El uso del software Open Source ofrece múltiples ventajas, si bien es importante entender y gestionar los posibles riesgos asociados:
- Una de las ventajas de utilizar software Open Source es su posible uso como infraestructura (sistemas operativos, servidores web, bases de datos, etc.). En este caso, se consigue ahorrar costes de licencias.
- Por otro lado, una empresa puede incrementar el valor añadido que aporta en sus productos, capturando enfoques o desarrollos novedosos o relevantes para sus soluciones que hayan sido desarrolladas por terceros ajenos a la empresa.
- Finalmente, contribuyendo al desarrollo de Open Source, una empresa puede construir una buena reputación, haciéndola más atractiva para los desarrolladores y para otras empresas que busquen colaboraciones.
Aunque tradicionalmente se ha considerado difÃcil obtener un retorno en el ámbito del Open Source (puesto que muchos proyectos fueron inicialmente creados de manera altruista), se han desarrollado distintos modelos de negocio que han ido surgiendo con el tiempo, lo que ha hecho que muchas empresas evolucionen dicho modelo (incluso en muchos casos coexisten varios de ellos):
- Una forma de comercializar el software Open Source es a través de la oferta de servicios (por ejemplo, mediante el soporte técnico o servicios de consultoría, lo que incluye el servicio de empaquetamiento o instalación de software en el entorno empresarial para su utilización en la actividad principal). Esta forma de comercializar el software Open Source es la primera que demostró ser una forma viable de negocio, con empresas a la cabeza como Red Hat o Suse.
- Otra modalidad centrada en la comercialización directa del software consiste en el modelo multi-licensing, en el que, por un lado, se proporciona el código de forma abierta bajo una licencia copyleft GNU para su uso en otros proyectos Open Source; por otro lado, se da la posibilidad de adquirir una licencia comercial o subscripción que concede derechos de propiedad y permite redistribuir versiones propietarias sin distribuir el código bajo una licencia GNU. Algunos ejemplos conocidos de esta modalidad los ofrecen grandes empresas en el campo de las bases de datos como MySQL, con la gratuita Community Edition y su versión de pago Enterprise, de manera similar a MongoDB. Este modelo de negocio trata de crear oportunidad de negocio segmentando el mercado a través de la utilidad derivada de las distintas licencias que conceden al software un determinado uso.
- Asimismo, una nueva forma de comercializar el software Open Source es el Open core: ofrecer, mantener y contribuir a una versión Open Source gratuita del código, normalmente más ligada a la comunidad de desarrolladores, a la par que se ofrecen extensiones o nuevas funcionalidades de pago complementarias al core Open Source. Estos servicios pueden incluir herramientas de programación, almacenamiento en nube, o gestión y mantenimiento de infraestructuras (por ejemplo, empresas como Cloudera, GitLab o Aiven representan casos asociados a estos servicios).
Sin embargo, el ecosistema Open Source no está exento de riesgos. Según Red Hat46, los principales obstáculos en la adopción de desarrollos Open Source que más peso tienen para las empresas son aspectos como la seguridad del código (puesto que al compartir el código fuente de manera abierta, el software puede ser más susceptible a ataques, a pesar de que constantemente la comunidad analiza y contribuye a arreglar posibles brechas de seguridad), el nivel de soporte, la compatibilidad entre versiones o la falta de habilidades dentro de la organización. Adicionalmente, desde un punto de vista legal, las licencias comerciales Open Source habitualmente no son tan claras como las del software comercial, lo que puede suponer un riesgo jurídico en la comercialización de productos. Además, las licencias GNU obligan a distribuir el código fuente de versiones propietarias que partan de una versión original Open Source, lo cual puede no ser del agrado de las compañías.
Conclusiones
El Open Source ha permitido potenciar el desarrollo del software de forma abierta y colaborativa, incentivando así un modelo de desarrollo global y descentralizado. Esto ha impulsado el proceso de desarrollo, dotándolo de distintas ventajas, como mayor velocidad, mayor capacidad de innovación, disminución de costes, interoperabilidad e intercambio de ideas y conocimiento.
Cada vez más, universidades, empresas y particulares adoptan el enfoque Open Source, refuerzan la comunidad e implementan distintos ecosistemas, ampliando el alcance de los mismos. Todo ello ha generado una tendencia que seguirá consolidándose en el futuro. No obstante, la adopción de sistemas de desarrollo Open Source requiere que las empresas realicen una inversión adicional, puesto que han de transformarse para incorporar el Open Source en los procesos productivos, asegurando la viabilidad y seguridad de los sistemas, y desarrollando capacidades a través de una formación especializada.
La newsletter “Modelización por componentes" ya está disponible para su descarga en la web de la Cátedra tanto en español como en inglés.