Hacia una inteligencia artificial sostenible
La Cátedra iDanae (inteligencia, datos, análisis y estrategia) en big data y analytics, creada en el marco de colaboración de la Universidad Politécnica de Madrid (UPM) y Management Solutions, publica su newsletter trimestral correspondiente al 1T24 sobre inteligencia artificial y sostenibilidad
Hacia una IA sostenible
Introducción
La inteligencia artificial (IA) ha surgido como una fuerza transformadora en diversos sectores, prometiendo redefinir la vida, el trabajo y las interacciones humanas. Sin embargo, el despliegue generalizado de la IA requiere un consumo significativo de recursos, lo que a menudo implica la utilización de una amplia infraestructura informática y aceleradores de hardware avanzados. Esto, unido al entrenamiento de algoritmos sofisticados en conjuntos de datos grandes y diversos, puede precipitar un consumo sustancial de electricidad. Dada la variedad de mix energéticos en los distintos países, las prácticas predominantes en la generación y distribución de electricidad contribuyen a la emisión de gases de efecto invernadero (GEI) a la atmósfera. Por consiguiente, es importante evaluar las implicaciones del desarrollo y la aplicación de la IA en la huella de carbono tanto de las personas como de las empresas, destacando el impacto medioambiental de los avances tecnológicos en este ámbito.
La capacidad de cálculo necesaria para el desarrollo y la comercialización de modelos de machine learning más avanzados se ha duplicado aproximadamente cada cinco o seis meses desde 2010, lo que ha aumentado el consumo de energía. Estudios recientes han revelado que el entrenamiento de algunos modelos de IA puede provocar emisiones de dióxido de carbono equivalentes a unas 284 toneladas métricas, una cifra comparable a más de 41 vuelos de ida y vuelta entre Nueva York y Sydney. Esta revelación saca a la luz el importante consumo de energía y las subsiguientes emisiones de carbono asociadas no sólo al entrenamiento de estos complejos modelos, sino también a sus operaciones de inferencia (esto es, el procesamiento y análisis de datos en tiempo real para proporcionar ideas), que se acumulan continuamente a medida que los servicios de IA se escalan globalmente para satisfacer la demanda de los usuarios.
Dada la rápida adopción de la IA y su integración en las funciones esenciales de la empresa, los directivos de las empresas deben afrontar este doble reto con perspicacia. La búsqueda de la innovación debe equilibrarse con un compromiso con la sostenibilidad, garantizando que el despliegue de las tecnologías de IA se alinea con objetivos más amplios de responsabilidad social corporativa y gestión medioambiental.
Todas estas necesidades dan lugar al concepto de algoritmos verdes. Schwartz introdujo el término Green IA para referirse a "Investigación en IA que produce resultados novedosos teniendo en cuenta el coste computacional". Este proceso de hacer más sostenible el desarrollo de la IA se perfila como una posible solución al problema de los algoritmos de alto consumo energético necesarios para entrenar y utilizar los modelos de IA. Por lo tanto, los algoritmos verdes de IA están diseñados para minimizar el impacto medioambiental de la informática, en particular reduciendo el consumo de energía y las emisiones de carbono asociadas a los modelos de IA y a sus procesos de entrenamiento. Estos algoritmos pretenden lograr una computación eficiente a través de diversas estrategias, como la optimización de la eficiencia algorítmica, la compresión de los modelos o el empleo de modelos menos intensivos desde el punto de vista computacional, sin comprometer el rendimiento.
Además, desde el punto de vista normativo, la Unión Europea también ha tomado medidas para abordar estos retos de sostenibilidad planteados por IA a través del reglamento recientemente aprobado de la Ley de IA. Está previsto que se convierta en uno de los marcos reguladores de la IA más completos a escala mundial, para garantizar que los sistemas de IA se desarrollen y utilizados de forma segura, ética y respetuosa con los derechos fundamentales, incluida la sostenibilidad medioambiental. Se trata, por tanto, de un paso más hacia el desarrollo y el uso de la IA de manera sostenible.
Para reflexionar sobre estas ideas, este whitepaper pretende analizar posibles enfoques de la IA sostenible y, a continuación, exponer dos casos prácticos de uso sobre cómo la IA puede contribuir a una economía más sostenible.
Un enfoque de la IA sostenible
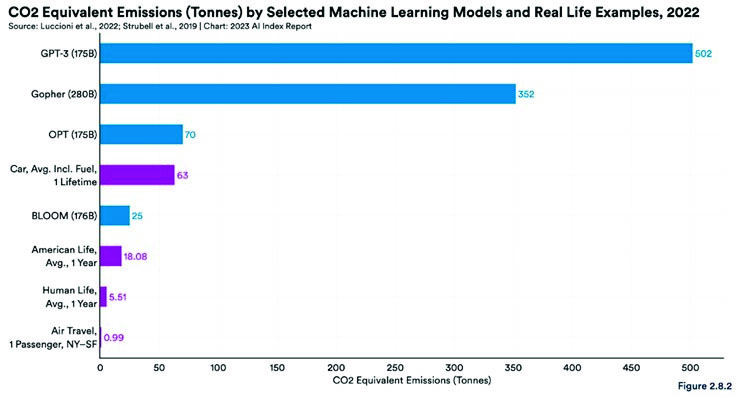
El impacto medioambiental de IA, y en particular de la IA generativa (GenAI), es una preocupación creciente a medida que estas tecnologías se integran cada vez más en la vida de las empresas y los individuos, ya que el ciclo de vida de los sistemas basados en estos modelos presenta un elevado consumo energético. Por ejemplo, el entrenamiento de Large Language Models (LLM) requiere grandes cantidades de datos y múltiples iteraciones de entrenamiento para estimar los miles de millones de parámetros presentes en el modelo. Esto conlleva un importante consumo eléctrico y grandes emisiones de carbono, especialmente en modelos basados en arquitecturas de transformadores como OpenAI GPT-4, Google Gemini o Anthropic Claude, entre muchos otros. Tanto el consumo eléctrico, que evalúa la eficiencia energética a través de KWh, como los equivalentes de CO2, que miden las toneladas de emisiones de carbono, son las métricas más habituales para medir el impacto medioambiental de los modelos de IA. Por ejemplo, GPT3, utilizando 175.000 millones de parámetros, emitió 100 veces las emisiones de un individuo en un año de su vida (véase la figura 1).
Sin embargo, el consumo de energía utilizado para entrenar el modelo suele verse superado por la fase de inferencia, cuando millones de usuarios comienzan a enviar peticiones al modelo entrenado por LLM. Los recursos de memoria, la potencia de procesamiento necesaria para ejecutar estos modelos y el mantenimiento de la infraestructura contribuyen al consumo total de energía.
Aunque no se dispone de toda la información (tiempo y recursos utilizados) de los cálculos requeridos para la inferencia, en N. Maslej se presentan resultados de rendimiento de inferencia y consumo de energía para las versiones pequeña (7 / 13 mil millones de parámetros) y grande (65 mil millones de parámetros) del LLM Llama desarrollado por Meta. Utilizando diferentes configuraciones de memoria y GPU, los resultados obtenidos resaltan que a pesar de emplear hardware de gama alta (como las GPUs V100 y A100), una parte considerable de la memoria de la GPU permanece infrautilizada, lo que sugiere una oportunidad para compartir recursos de forma más eficiente y limitar la potencia de la GPU, lo que podría reducir significativamente el consumo de energía durante las tareas de inferencia.
En la búsqueda de una IA sostenible o verde, se han explorado varias estrategias para minimizar el impacto medioambiental de las operaciones de IA. Estas estrategias incluyen la optimización del despliegue de modelos de IA y del hardware de energía, el empleo de técnicas de compresión de modelos como la cuantización y la poda para reducir el tamaño y la velocidad de los modelos de IA, el desarrollo de algoritmos verdes que requieran menos potencia computacional, transferir las operaciones de IA a fuentes de energía renovables para reducir la huella de carbono, y aplicar el escalado dinámico y la gestión de carga para optimizar la utilización de los recursos. Juntos, estos enfoques ofrecen una hoja de ruta multifacética hacia sistemas de IA más eficientes energéticamente y responsables con el medio ambiente, abordando tanto la urgente necesidad de sostenibilidad como la continua demanda de capacidades avanzadas de IA:
- Optimización de hardware y despliegue de modelos: La utilización de hardware energéticamente eficiente como GPUs y TPUs, diseñado específicamente para tareas de IA, mejora significativamente la eficiencia computacional. Esta estrategia no sólo acelera la velocidad de procesamiento, sino que también minimiza el consumo de energía durante el entrenamiento y la inferencia de modelos de IA. Al optimizar el software para aprovechar al máximo las capacidades de estas unidades de hardware especializadas, las organizaciones pueden lograr reducciones sustanciales en el uso de energía, contribuyendo a operaciones de IA más sostenibles.
- Técnicas de compresión de modelos: La aplicación de écnicas de compresión de modelos como la cuantización, que reduce la precisión de las representaciones numéricas en los cálculos aritméticos, y la poda, que elimina los pesos innecesarios en el modelo de IA, puede disminuir significativamente tanto el tamaño de los modelos de IA como sus requisitos computacionales. Estos métodos mejoran la velocidad de los modelos de IA y al mismo tiempo reducen el consumo de energía, lo que hace que los sistemas de IA sean más eficientes y respetuosos con el medio ambiente.
- Algoritmos verdes: Centrados en el desarrollo de algoritmos que requieran menos potencia de cálculo sin comprometer su eficacia, los algoritmos verdes pretenden reducir el impacto medioambiental de la IA. Esto implica una investigación innovadora para crear modelos y algoritmos de IA que no solo sean potentes, sino que también estén diseñados teniendo en cuenta la eficiencia energética, abordando el doble reto de mantener un alto rendimiento y minimizar las emisiones de carbono.
- Fuentes de energía renovable: La transición de los centros de datos que alimentan las operaciones de IA a fuentes de energía renovables es un paso fundamental para reducir la huella de carbono de las actividades de IA. Al abastecerse de energía procedente de fuentes renovables para las fases de entrenamiento e inferencia de los modelos de IA, las empresas pueden reducir significativamente el impacto medioambiental de sus operaciones de IA, alineando el avance tecnológico con los objetivos de sostenibilidad. Es importante que esta transición no se traduzca en un mayor consumo de agua para refrigeración.
- Escalado dinámico de recursos: Al ajustar dinámicamente los recursos computacionales en función de la demanda actual, esta estrategia garantiza que no se desperdicie energía durante los periodos de bajo uso. Este enfoque de la asignación de recursos no sólo ahorra energía, sino que también optimiza la eficiencia global de los sistemas de IA, lo que conduce a una utilización más sostenible de los recursos computacionales en diferentes escenarios.
Mientras que se exploran estrategias para una IA más eficiente desde el punto de vista energético, también es importante considerar el panorama normativo que configura el desarrollo y la implantación de estas tecnologías y promueve prácticas sostenibles. La Ley de IA de la Unión Europea, que está llamada a convertirse en uno de los marcos normativos más completos en materia de IA a escala mundial, aborda esta cuestión solicitando a los proveedores de modelos de propósito general (por ejemplo, Large Language Models) especificaciones de diseño del modelo y del proceso de entrenamiento, información sobre los datos utilizados para el entrenamiento, las pruebas y la validación, los recursos informáticos utilizados para entrenar el modelo, así como la notificación del consumo de energía conocido o estimado del modelo basado en la información sobre los recursos informáticos utilizados (Ley de IA, artículo 53, apartado 1, letra (a)). Esto establece una directriz y una primera aproximación para concienciar y empezar a poner algunas prácticas de control a las organizaciones que implementan y entregan sistemas de IA para ser utilizados a escala global.
Aplicaciones prácticas
Como se ha señalado en la sección anterior, la rápida aplicación de la inteligencia artificial exige un debate permanente sobre su sostenibilidad y su impacto ambiental. A medida que las tecnologías de IA, en particular LLM, se han convertido en parte integrante del procesamiento y el análisis de grandes cantidades de datos, su demanda energética y computacional se ha disparado. Además de los LLM, existen otras tecnologías de IA que también procesan enormes cantidades de datos, como los capturados a través de los teléfonos móviles y de las redes de sensores. Aunque cada uno de estos modelos individuales de IA puede consumir una pequeña cantidad de energía (tanto de forma independiente como en comparación con LLM), el gran número de esos modelos que podrían instalarse en muchos dispositivos diferentes requiere una atención especial. Además, este problema se agrava por el hecho de que con frecuencia se recogen nuevos datos, lo que permite un reentrenamiento más frecuente. Reconociendo todos estos retos, se presentan dos casos de uso innovadores para debatir estas preocupaciones y mostrar cómo las prácticas de sostenibilidad podrían integrarse en la IA en todas las industrias.
Caso práctico 1: GreenLightningAI
Se ha prestado mucha atención a cómo se distribuye el consumo de energía a lo largo del proceso de entrenamiento de los modelos de IA. Sin embargo, dado que los datos cambian con el tiempo, es necesario reconocer nuevos patrones en los datos y actualizar los modelos de IA en consecuencia para preservar la precisión del modelo. A medida que se disparan la demanda y la complejidad de las aplicaciones de IA, incluso con mejoras algorítmicas, matemáticas y de hardware avanzadas, el proceso de entrenamiento de las complejas Deep Neural Networks (DNN) sigue siendo costoso desde el punto de vista económico y medioambiental. Las optimizaciones tradicionales para el entrenamiento de DNN están llegando a sus límites, lo que hace necesario un enfoque fundamentalmente diferente. GreenLightningAI es una solución desarrollada por Qsimov Quantum Computing en colaboración con la Universitat Jaume I de Castelló y la Universitat Politècnica de València. Ha sido completamente implementada, probada y evaluada por Management Solutions en un proyecto dirigido por Qsimov Quantum Computing. Se trata de un innovador sistema de IA diseñado para hacer frente a los crecientes costes computacionales y medioambientales asociados al entrenamiento de DNN. Más concretamente, el objetivo de los autores es simplificar, acelerar y hacer más eficiente desde el punto de vista medioambiental el reentrenamiento de los modelos de IA.
La solución propuesta incluye la disociación del conocimiento estructural y cuantitativo en los sistemas de IA. Emplea un modelo lineal para emular el comportamiento lineal a trozos de la DNN. Este modelo se subdivide para cada muestra específica, almacenando la información necesaria para la selección de subconjuntos (información estructural) por separado de los parámetros del modelo lineal (conocimiento cuantitativo). Dado que la información estructural es mucho más estable que el conocimiento cuantitativo, solo es necesario volver a entrenar los parámetros del modelo lineal. Este innovador diseño permite combinar fácilmente varias copias del modelo entrenadas en diferentes conjuntos de datos, lo que facilita algoritmos de reentrenamiento más rápidos y verdes, incluidos el reentrenamiento incremental y el reentrenamiento incremental federado.
El conocimiento estructural está representado por los patrones de activación de la red neuronal para las distintas muestras. Cada patrón de activación consiste en un conjunto de trayectorias activas. La estabilidad del conocimiento estructural se atribuye a la captura temprana de características de alto nivel en el entrenamiento, lo que indica que estas características de alto nivel se han aprendido de forma efectiva. El sistema se define mediante dos elementos:
- Selector de rutas: que identifica las trayectorias de las neuronas activas para cada muestra individual y permanece invariable durante el reentrenamiento.
- Estimador: que contiene el modelo lineal y utiliza los resultados del selector de trayectorias para obtener dicho modelo lineal para cada muestra individual, tanto para la inferencia como para el (re)entrenamiento. Los parámetros del modelo lineal se actualizan durante el
(re)entrenamiento.
Entre las ventajas de este diseño del sistema, cabe destacar que el estimador consiste únicamente en una capa oculta, lo que permite un entrenamiento mucho más rápido y evitar los problemas relacionados con la anulación del gradiente. Además, dado que se utiliza un sistema lineal, se permite el reentrenamiento incremental, lo que se traduce en una esperada fuerte reducción de los tiempos de reentrenamiento. También proporciona interpretabilidad directa.
Este nuevo prometedor método de entrenamiento valida el potencial de los algoritmos verdes en IA, alineándose con los objetivos de sostenibilidad medioambiental mediante la optimización de los procesos de entrenamiento para un menor consumo de energía. Los experimentos validan la hipótesis de que la información estructural se estabiliza antes que el conocimiento cuantitativo y puede mantenerse sin modificaciones durante el reentrenamiento, al tiempo que se consigue una precisión de validación comparable a la de los métodos de reentrenamiento tradicionales, pero con un uso de recursos mucho menor.
Caso práctico 2: Aprendizaje automático interpretable para estimar las emisiones de las empresas
La IA debe analizarse desde el punto de vista de la sostenibilidad, pero también puede utilizarse como herramienta para ayudar a las organizaciones a identificar y cerrar las brechas de sostenibilidad. Una de las brechas que tienen algunas empresas es reportar las emisiones de gases de efecto invernadero (GEI) de Scope 1 y Scope 21 porque en algunas ocasiones dicha información no es fácil de calcular. Los informes de sostenibilidad sobre estas emisiones son a veces estimativos, ya que no todas las empresas disponen de datos precisos sobre las emisiones. Incluso las entidades reguladoras son conscientes de lo complicada que puede resultar esta tarea, por lo que permiten el uso de estimaciones o cálculos basados en la mejor información disponible cuando no se dispone de datos.
Un estudio reciente introduce un modelo de machine learning para estimar las emisiones de gases de efecto invernadero de Scope 1 y Scope 2 de las empresas, diseñado para ser transparente e interpretable. Su objetivo es proporcionar estimaciones precisas de las emisiones en diferentes sectores, países y tamaños de ingresos, contribuyendo a un enfoque más estandarizado de los informes de sostenibilidad.
El sistema emplea ajustes de regresión, separando las emisiones de Scope 1 y Scope 2 en dos modelos. Estos modelos toman características que proporcionan una visión global de las operaciones, la salud financiera y el impacto medioambiental de una empresa. Las características se dividen en cuatro grupos:
- Características generales: Año, País.
- Clasificación industrial: Niveles de clasificación BICS 1 a 7, Clasificación de exposición a nuevas energías.
- Características financieras: Empleados, gastos de capital, valor de la empresa, ingresos, propiedad, planta y equipo (bruto y neto), depreciación, agotamiento y amortización, consumo de energía, potencia total generada.
- Características regionales: Mezcla energética del país, Intensidad de carbono, existencia de un sistema de comercio de derechos de emisión (ETS) o impuestos sobre el carbono.
Las emisiones de GEI objetivo se obtienen de fuentes de alta calidad como CDP y Bloomberg, dando prioridad a las emisiones auditadas y no modelizadas. Los datos se someten a un proceso de depuración para corregir la variabilidad y las incoherencias, y las emisiones notificadas en distintos momentos se ajustan a un marco temporal anual coherente. A continuación, el sistema divide el conjunto de datos en conjuntos de entrenamiento, validación y prueba, y optimiza el modelo para minimizar el error cuadrático medio. Se utilizan Gradient Boosting Decision Trees (GBDT), como LightGBM, por su capacidad para aprender formas funcionales más genéricas y manejar patrones no lineales. El modelo se entrena para estimar el logaritmo decimal de las emisiones de GEI con el fin de manejar eficazmente la naturaleza sesgada de los datos de emisiones.
La interpretabilidad de este modelo reside en el uso de los valores de Shapley, un concepto tomado de la teoría de juegos y aplicado al machine learning para evaluar la contribución de cada característica a las predicciones del modelo. Los valores de Shapley proporcionan una forma sistemática de determinar cómo influye cada característica de entrada en la salida del modelo, ofreciendo así información sobre el proceso de toma de decisiones del modelo de machine learning. Estos valores proporcionan una explicación detallada de la predicción, haciendo que las decisiones del modelo sean transparentes y comprensibles, lo que resulta especialmente valioso para evaluar la importancia de las variables en modelos complejos como los que estiman las emisiones de gases de efecto invernadero. También aborda una crítica común a los modelos Gradient Boosted Decision Trees, conocidos por su rendimiento superior en el manejo de datos tabulares, pero criticados por su falta de interpretabilidad.
Según los resultados presentados, el modelo muestra un buen rendimiento global, con resultados estables en los distintos sectores, países y deciles de ventas. En concreto, el modelo muestra un rendimiento especialmente bueno en los sectores más emisores, lo que pone de manifiesto la eficacia de la metodología de sectorización elegida y la capacidad del modelo para adaptarse a la compleja variabilidad inherente a los datos sobre emisiones de GEI. Además, el enfoque del sistema en materia de formación y validación garantiza que el modelo esté bien equipado para manejar los datos más recientes y relevantes, lo que aumenta aún más su precisión y fiabilidad a la hora de estimar las emisiones de GEI en una amplia gama de empresas e industrias.
Conclusiones
El importante impacto medioambiental de la inteligencia artificial, en particular el considerable consumo de energía y las emisiones de carbono derivadas tanto del desarrollo como de la aplicación de grandes modelos lingüísticos, pone de manifiesto la necesidad de un cambio hacia prácticas de IA sostenible. Estas prácticas, que incluyen el despliegue optimizado de modelos, la compresión de modelos, el desarrollo de algoritmos energéticamente eficientes, la adopción de fuentes de energía renovables y el escalado dinámico de recursos, representan un enfoque holístico para reducir la huella de carbono de la IA.
A través de aplicaciones prácticas, como métodos innovadores para el reentrenamiento de modelos de IA y modelos de machine learning para estimar las emisiones de las empresas, se ha ilustrado el potencial de la IA como herramienta para mejorar la sostenibilidad medioambiental. Estos ejemplos demuestran que la integración de la sostenibilidad en el desarrollo de la IA no solo mitiga su impacto ambiental, sino que también aprovecha su potencial para apoyar esfuerzos de sostenibilidad más amplios en diversos sectores.
Los marcos normativos, como el AI Act de la Unión Europea, van a desempeñar un papel importante en la promoción de prácticas sostenibles en el sector de la IA, estableciendo normas de transparencia en el consumo de energía y la aplicación de tecnologías respetuosas con el medio ambiente.
En resumen, equilibrar la innovación de la IA con la protección del medio ambiente es de vital importancia. Adoptando prácticas de IA sostenible, respetando las normas reglamentarias y explorando aplicaciones sostenibles, se puede avanzar hacia un futuro en el que la IA contribuya positivamente a los objetivos medioambientales, garantizando que los avances tecnológicos progresen en armonía con la sostenibilidad.
La newsletter ya está disponible para su descarga en la web de la Cátedra tanto en español como en inglés.